
컨테이너에 대한 사전 정보를 알아봤으니, 실제 K8S(Kubernetes)에서의 네트워크를 알아보자.
스터디를 위한 구성
스터디를 위한 K8S 구성은 AWS에 구성하였으며, 아래와 같다.
root@k8s-m:~# kubectl get node -owide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-m NotReady control-plane 57s v1.30.5 192.168.10.10 <none> Ubuntu 22.04.5 LTS 6.5.0-1024-aws containerd://1.7.22
k8s-w0 NotReady <none> 37s v1.30.5 192.168.20.100 <none> Ubuntu 22.04.5 LTS 6.5.0-1024-aws containerd://1.7.22
k8s-w1 NotReady <none> 35s v1.30.5 192.168.10.101 <none> Ubuntu 22.04.5 LTS 6.5.0-1024-aws containerd://1.7.22
k8s-w2 NotReady <none> 37s v1.30.5 192.168.10.102 <none> Ubuntu 22.04.5 LTS 6.5.0-1024-aws containerd://1.7.22
root@k8s-m:~# calicoctl version
Client Version: v3.28.1
Git commit: 601856343
Cluster Version: v3.28.1
Cluster Type: k8s,bgp,kubeadm,kdd- K8S v1.30
- Nodes
- OS(Ubuntu 22.04 LTS)
- 2개의 다른 서브넷 구성 : 192.168.10.0/24 대역과 192.168.20.0/24 대역
- CNI(Calico v3.28.1, IPIP, NAT enable)
- IPTABLES proxy mode
CNI란?
"Container Network Interface"로 컨테이너 환경에서 네트워크 인터페이스를 설정하고 관리하기 위한 표준 인터페이스이다. K8S의 네트워크 요구사항을 만족하기 위한 일종의 규칙이라고 볼 수 있다.
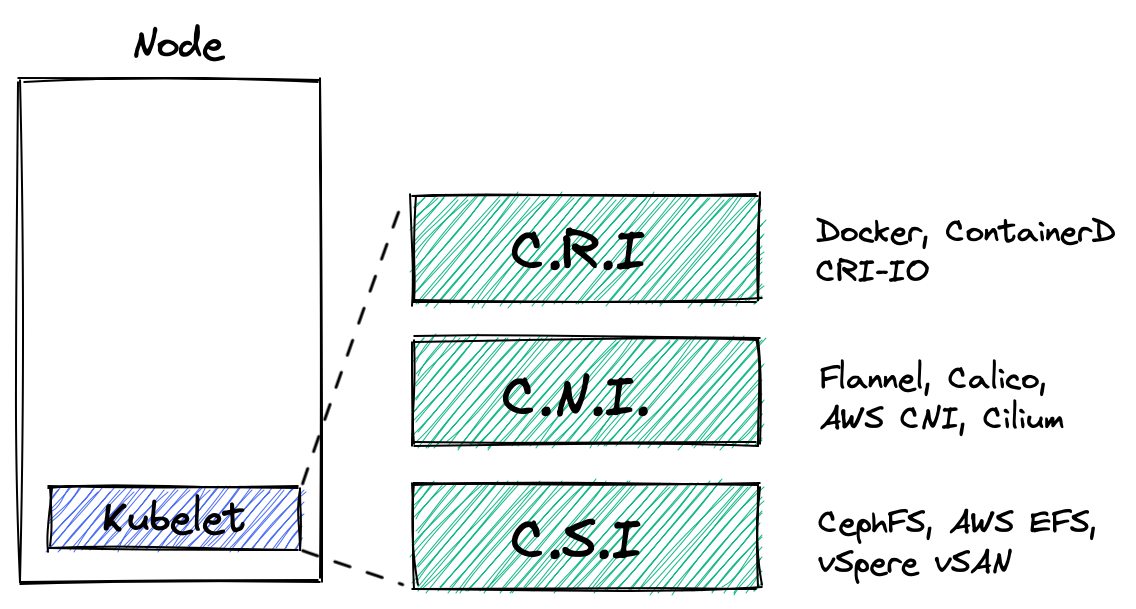
이런 CNI에 대한 상세 스펙은 아래의 문서에서 확인할 수 있다.
CNI가 없다면, 라우팅 구성, eth 장치 구성, IP할당, 네트워크 네임스페이스 구성 등을 Pod가 생성되고 삭제될 때마다 수동으로 해줘야한다.
CNI 플러그인
이러한 인터페이스를 만족시키는 프로그램을 CNI 플러그인이라고 하며 다양한 종류가 있다.
- Calico : https://www.tigera.io/project-calico/
- Cillium : https://cilium.io/
Flannel : https://github.com/flannel-io/flannel - 그 외 다양한 CNI 플러그인 : https://github.com/containernetworking/cni#3rd-party-plugins
각 CNI 플러그인 별로 장단점이 있으므로 관심이 있다면 아래 링크를 통해서 어떤 점이 내 K8S 구성에 적절한지 보고 선택하면 좋을 것이다.
Benchmark results of Kubernetes network plugins (CNI) over 40Gbit/s network [2024]
This article is a new run of my previous benchmark (2020, 2019 and 2018), now running Kubernetes 1.26 and Ubuntu 22.04 with CNI version…
itnext.io
CNI 플러그인 주요 역할
CNI에서는 아래에 명시된 6가지 주요 동작을 지원한다.
https://github.com/containernetworking/cni/blob/main/SPEC.md#cni-operations
- ADD 작업 : 컨테이너를 네트워크에 추가하거나, 기존 네트워크 설정을 수정하는 작업
- DEL 작업 : 네트워크에서 컨테이너를 제거하거나, 이전에 적용된 네트워크 설정을 해제하는 작업
- CHECK 작업 : 기존 컨테이너의 네트워크 상태가 예상대로인지 확인하는 작업
- STATUS 작업 : 네트워크 플러그인이 ADD 요청을 처리할 준비가 되어 있는지 확인하는 작업
- VERSION 작업 : 플러그인이 지원하는 버전 정보를 반환하는 작업
- GC(Garbage Collection) 작업 : 사용되지 않는 네트워크 리소스를 정리하는 작업
(추가) 나중에 더 파보기
따로 좀 찾아보다가 재밌는 글을 찾았는데 bash script로 해당 CNI 플러그인을 만드는 글이었다.
테스트를 좀 해보다가 해당 글 작성이 밀려서 나중으로 미뤘는데, 현재 버전에 맞게 테스트를 해보면 Pod간 통신을 이해하기 더 좋을 것 같다.
이번 스터디에서는 Calico를 사용해서 네트워크를 확인해본다.
Pod 배포 전 초기 구성 확인
CNI 동작을 확인해보기 위해 현재 초기 구성을 확인해본다.
Pod 배포는 1번 노드에서 수행할 예정이므로 1번 노드에서 확인한다.
# tunl0가 생성되어있고, 172.16.158.0/32를 할당받음
root@k8s-w1:~# ip -c -d addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 promiscuity 0 minmtu 0 maxmtu 0 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
...
2: ens5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
link/ether 02:f4:40:5c:3d:8b brd ff:ff:ff:ff:ff:ff promiscuity 0 minmtu 128 maxmtu 9216 numtxqueues 2 numrxqueues 2 gso_max_size 65536 gso_max_segs 65535 parentbus pci parentdev 0000:00:05.0
altname enp0s5
inet 192.168.10.101/24 metric 100 brd 192.168.10.255 scope global dynamic ens5
valid_lft 3498sec preferred_lft 3498sec
...
3: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 8981 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0 promiscuity 0 minmtu 0 maxmtu 0
ipip any remote any local any ttl inherit nopmtudisc numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
inet 172.16.158.0/32 scope global tunl0
valid_lft forever preferred_lft forever
# node에서는 root 네임스페이스를 사용
root@k8s-w1:~# lsns -t net
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531840 net 131 1 root unassigned
root@k8s-w1:~# ip -c route | sort
172.16.116.0/24 via 192.168.10.10 dev tunl0 proto bird onlink
172.16.184.0/24 via 192.168.10.102 dev tunl0 proto bird onlink
172.16.34.0/24 via 192.168.20.100 dev tunl0 proto bird onlink
192.168.0.2 via 192.168.10.1 dev ens5 proto dhcp src 192.168.10.101 metric 100
192.168.10.0/24 dev ens5 proto kernel scope link src 192.168.10.101 metric 100
192.168.10.1 dev ens5 proto dhcp scope link src 192.168.10.101 metric 100
blackhole 172.16.158.0/24 proto bird
default via 192.168.10.1 dev ens5 proto dhcp src 192.168.10.101 metric 100
여기서 주의 깊게 볼 것은 bird로 표시된 라우팅인데, bird는 각 노드마다 존재하는 BGP 데몬이다.
이 bird 데몬은 다른 노드에 있는 데몬들과 라우팅 정보를 교환하는데, 여기서 bird로 표시된 대역대는 각 노드에서 관리하는 Pod의 네트워크 대역이다.
또 bird로 표시된 blackhole도 확인할 수 있는데, 해당 blackhole은 쓸모없어진 통신 패킷을 삭제하는데 사용된다.
단순하게 예를 들어서 설명하면 2개의 Pod A,B가 서로 통신을 수행하다 B Pod가 삭제되었다고 가정해보자. 이 때 A Pod에서 보낸 패킷은 라우팅에 의해서 B Pod가 있던 노드(혹은 터널)로 이동하고 해당 노드(혹은 터널)에서는 더 이상 존재하지 않는 IP에 대한 패킷이므로 최상위 매핑 규칙에 의해 default gateway로 전송되는 사례가 발생할 수 있다. 이런 경우 불필요한 패킷이 떠다니며 트래픽을 발생시키므로 삭제하기 위해 blackhole 라우팅이 사용된다.
조금 더 자세히 이해하고 싶으면 해당 github issue 토론을 보면 왜 blackhole 대역이 필요한지 등을 볼 수 있다.
같은 Node 내에서 Pod 간의 통신
하나의 Node에 Pod 2개를 배포하고 통신을 확인해보자.
# 출처 : https://github.com/gasida/NDKS
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
nodeName: k8s-w1
containers:
- name: pod1
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
---
apiVersion: v1
kind: Pod
metadata:
name: pod2
spec:
nodeName: k8s-w1
containers:
- name: pod2
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
curl -s -O https://raw.githubusercontent.com/gasida/NDKS/main/4/node1-pod2.yaml
kubectl apply -f node1-pod2.yaml
root@k8s-m:~# calicoctl get workloadendpoints
WORKLOAD NODE NETWORKS INTERFACE
pod1 k8s-w1 172.16.158.1/32 calice0906292e2
pod2 k8s-w1 172.16.158.2/32 calibd2348b4f671번 노드에서 Pod가 생성되고 초기 상태와 비교해보자.
root@k8s-w1:~# ip -c -d addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
...
2: ens5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
link/ether 02:f4:40:5c:3d:8b brd ff:ff:ff:ff:ff:ff promiscuity 0 minmtu 128 maxmtu 9216 numtxqueues 2 numrxqueues 2 gso_max_size 65536 gso_max_segs 65535 parentbus pci parentdev 0000:00:05.0
...
3: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 8981 qdisc noqueue state UNKNOWN group default qlen 1000
...
6: calice0906292e2@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8981 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-fe3f61e6-ddc0-89b3-109f-e970404aeaf1 promiscuity 0 minmtu 68 maxmtu 65535
veth numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
7: calibd2348b4f67@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8981 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-dbbe8c16-9d9c-41fb-967b-7a1b8224b510 promiscuity 0 minmtu 68 maxmtu 65535
veth numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
root@k8s-w1:~# lsns -t net
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531840 net 131 1 root unassigned /sbin/init
4026532218 net 2 28053 65535 0 /run/netns/cni-fe3f61e6-ddc0-89b3-109f-e970404aeaf1 /pause
4026532277 net 2 28077 65535 1 /run/netns/cni-dbbe8c16-9d9c-41fb-967b-7a1b8224b510 /pause
root@k8s-w1:~# ip -c route | sort
172.16.116.0/24 via 192.168.10.10 dev tunl0 proto bird onlink
172.16.158.1 dev calice0906292e2 scope link
172.16.158.2 dev calibd2348b4f67 scope link
172.16.184.0/24 via 192.168.10.102 dev tunl0 proto bird onlink
172.16.34.0/24 via 192.168.20.100 dev tunl0 proto bird onlink
192.168.0.2 via 192.168.10.1 dev ens5 proto dhcp src 192.168.10.101 metric 100
192.168.10.0/24 dev ens5 proto kernel scope link src 192.168.10.101 metric 100
192.168.10.1 dev ens5 proto dhcp scope link src 192.168.10.101 metric 100
blackhole 172.16.158.0/24 proto bird
default via 192.168.10.1 dev ens5 proto dhcp src 192.168.10.101 metric 1001번 노드에 새로운 장치 2개가 생성되었고, 네트워크 네임스페이스도 2개가 새로 생성되었다. 라우팅 테이블도 2개가 새로 추가된 것을 볼 수 있다.
각 Pod에 접속해서 네트워크 장치와 라우팅을 확인해보자.
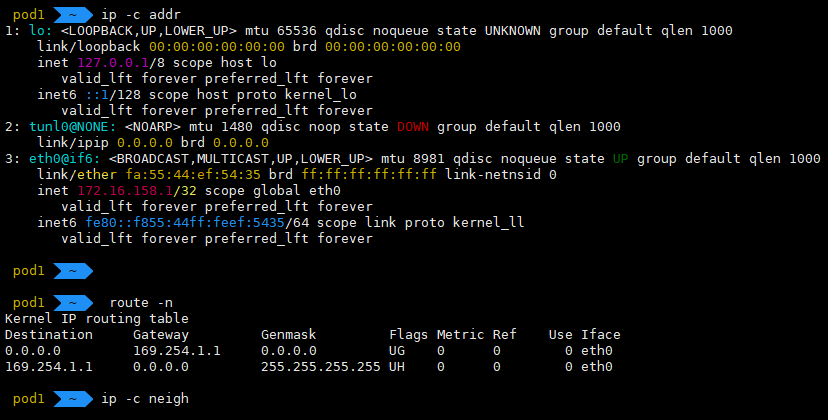
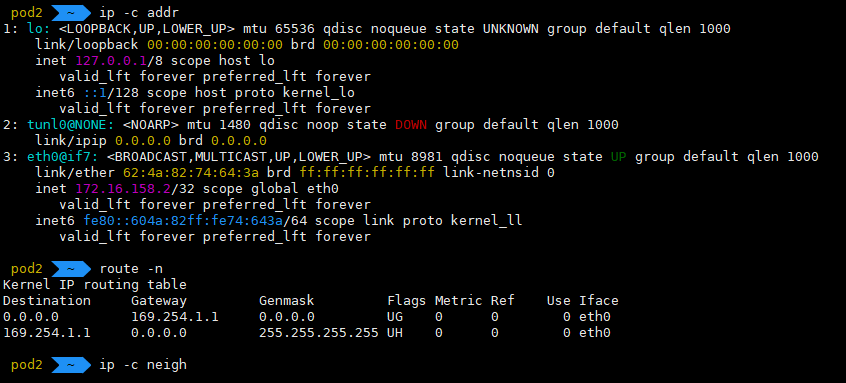
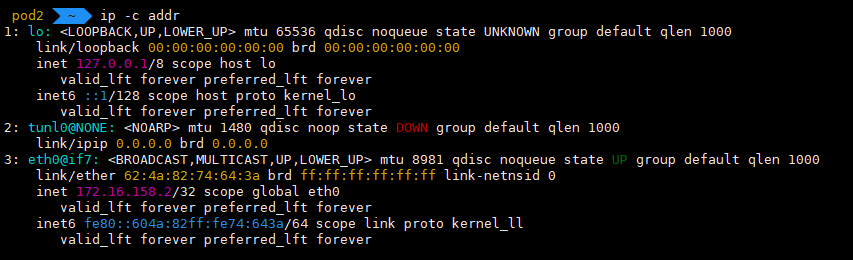
희안한게 eth0@if6, eth0@if7 장치에 Pod IP가 할당되어있고, 2개의 Pod 모두 라우팅 테이블이 기본으로 169.254.1.1로 잡혀있다. 이런 상황에서 Pod 간에 통신이 될까?

ping이 잘 간다. ARP 테이블을 확인해보면 169.254.1.1로 MAC주소가 잘 등록되어있다.
어떻게 통신하는 걸까? tcpdump를 통해 상세히 확인해보자.
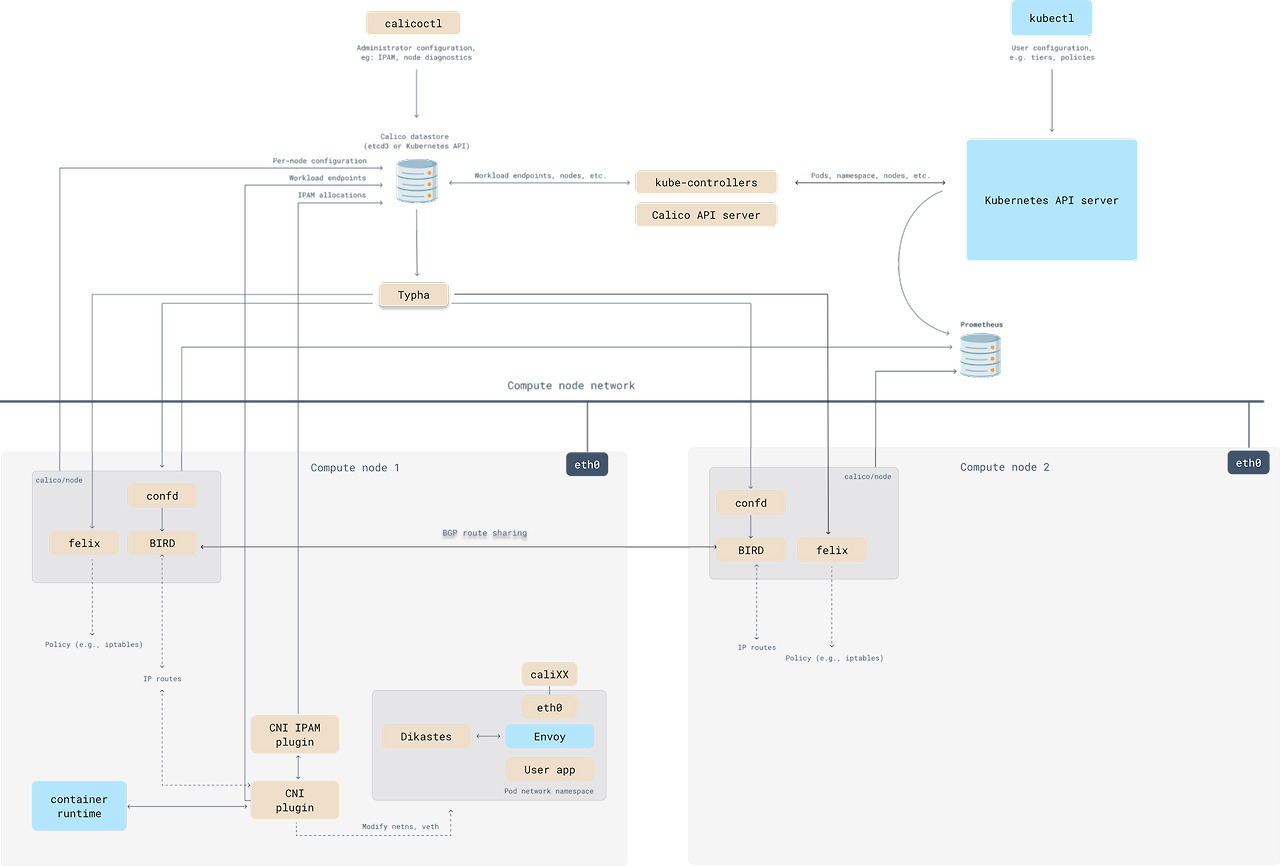
Pod간 통신 상세 분석
Calico CNI가 생성해준 네트워크 인터페이스를 통해 상세하게 알아보자.
(주의) 이 부분은 스터디 자료를 기반으로 한 테스트와 검색을 통해서 하나씩 찾아보면서 이해한 내용이라 다소 잘못된 내용이 있을 수 있으니 잘못된 내용은 공유 부탁드립니다.
# control-plane 노드에서 수행
root@k8s-m:~# calicoctl get workloadEndpoint
WORKLOAD NODE NETWORKS INTERFACE
pod1 k8s-w1 172.16.158.1/32 calice0906292e2
pod2 k8s-w1 172.16.158.2/32 calibd2348b4f67
# 1번 노드에서 수행
for file in /proc/sys/net/ipv4/conf/*/proxy_arp; do
ls -l $file | tr -s ' ' | cut -d' ' -f1-8 | tr '\n' ' '
echo -n "$file "
cat $file
done
-rw-r--r-- 1 root root 0 Sep 22 00:51 /proc/sys/net/ipv4/conf/all/proxy_arp 0
-rw-r--r-- 1 root root 0 Sep 21 23:54 /proc/sys/net/ipv4/conf/calibd2348b4f67/proxy_arp 1
-rw-r--r-- 1 root root 0 Sep 21 23:54 /proc/sys/net/ipv4/conf/calice0906292e2/proxy_arp 1
-rw-r--r-- 1 root root 0 Sep 22 00:51 /proc/sys/net/ipv4/conf/default/proxy_arp 0
-rw-r--r-- 1 root root 0 Sep 22 00:51 /proc/sys/net/ipv4/conf/ens5/proxy_arp 0
-rw-r--r-- 1 root root 0 Sep 22 00:51 /proc/sys/net/ipv4/conf/lo/proxy_arp 0
-rw-r--r-- 1 root root 0 Sep 22 00:51 /proc/sys/net/ipv4/conf/tunl0/proxy_arp 0
VETH1=calice0906292e2
tcpdump -i $VETH1 -nn
# tcpdump 후 1번 Pod에서 2번 Pod로 Ping 수행
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on calice0906292e2, link-type EN10MB (Ethernet), snapshot length 262144 bytes
...
01:15:00.108534 ARP, Request who-has 169.254.1.1 tell 172.16.158.1, length 28
01:15:00.108573 ARP, Reply 169.254.1.1 is-at ee:ee:ee:ee:ee:ee, length 28
01:15:00.108578 IP 172.16.158.1 > 172.16.158.2: ICMP echo request, id 77, seq 1, length 64
...
01:15:05.230514 IP 172.16.158.2 > 172.16.158.1: ICMP echo reply, id 77, seq 6, length 64
01:15:05.294411 ARP, Request who-has 172.16.158.1 tell 192.168.10.101, length 28
01:15:05.294459 ARP, Reply 172.16.158.1 is-at 86:e5:22:07:c3:f3, length 28
01:15:06.254448 IP 172.16.158.1 > 172.16.158.2: ICMP echo request, id 77, seq 7, lenARP 패킷을 통해 169.254.1.1이라는 IP가 172.16.158.1이라고 확인하고, 1번 Pod의 IP(172.16.158.1)가 192.168.10.101이라고 확인한다.
위의 통신 과정을 이해하려면 2가지를 이해해야 한다.
Proxy ARP 란?
ARP의 확장 기능으로 한 네트워크 호스트가 다른 호스트를 대신해서 ARP 요청에 응답할 수 있게 해주는 기능이다.
아까 proxy_arp 설정이 1로 되어있는 것을 확인했는데, 이 설정을 통해서 Node가 Pod의 IP 주소에 대한 ARP 요청에 대신 응답을 해줄 수 있는 것이다. 조금 더 자세히 설명하면 proxy_arp는 인터페이스가 다른 네트워크의 ARP 요청에 대해 대신 응답할 수 있게 해주는 Linux 커널 기능이다.
-rw-r--r-- 1 root root 0 Sep 21 23:54 /proc/sys/net/ipv4/conf/calibd2348b4f67/proxy_arp 1
-rw-r--r-- 1 root root 0 Sep 21 23:54 /proc/sys/net/ipv4/conf/calice0906292e2/proxy_arp 1따라서 이 설정을 0으로 바꾸면 당연하게도 잘되던 Pod 간의 통신은 막혀버린다.
(여러번 pod를 생성하고 삭제하다보니 IP가 변경되었는데, 172.16.158.6이 기존 Pod1번 172.16.158.1이다.)


위의 tcpdump에서 Pod1번(172.16.158.1)은 ping을 수행하기 위해 169.254.1.1의 MAC주소를 찾으려고 하고, Node에서는 Proxy ARP를 통해 ee:ee:ee:ee:ee:ee라고 응답한다. (더 정확하게는 Calico CNI의 veth에서 응답해주는 것으로 보인다.)
In some setups the kernel is unable to generate a persistent MAC address and so Calico assigns a MAC address itself. Since Calico uses point-to-point routed interfaces, traffic does not reach the data link layer so the MAC Address is never used and can therefore be the same for all the cali* interfaces.
스터디에서 알게된 내용으로 일부 커널이 고정 맥 주소 생성이 안되서, Calico가 자체 MAC을 생성한다고 한다.
또한 파드와 cali#(veth pair) 는 point-to-point routed interfaces 를 사용하기 때문에 호스트의 데이터링크 레이어(L2 Layer) 에 도달하지 않아서, 모든 cali# 가 동일한 맥 주소를 사용해도 문제가 없다고 한다.
169.254.1.1는 어떤 IP인가?
169.254.0.0/16 범위의 IP 주소는 link-local address라고 하는 예약된 IP 주소이다.
해당 대역의 IP는 IANA (Internet Assigned Numbers Authority)에 의해 특별한 용도로 예약되어있어, 일반적인 인터넷 통신에 사용되지 않는다.
용도는 다양한데, 쉽게 볼 수 있는 경우는 Windows 시스템에서 이 범위를 APIPA (Automatic Private IP Addressing)로 사용해 DHCP가 동작하지 않을 경우 임의로 할당해 사용하기도 한다.
Calico CNI에서는 Pod의 기본 게이트웨이로 설정해 특별하게 사용한다.
Calico tries hard to avoid interfering with any other configuration on the host. Rather than adding the gateway address to the host side of each workload interface, Calico sets the
proxy_arp
flag on the interface. This makes the host behave like a gateway, responding to ARPs for 169.254.1.1 without having to actually allocate the IP address to the interface.
Ping이 수행되는 과정
이제 그럼 어떻게 같은 Node 내에서 서로 다른 Pod간에 통신이 수행되는지 하나씩 보자.
1. Pod1(172.16.158.1)에서 Ping 명령을 수행해 Pod2(172.16.158.2)로의 ICMP echo Request 패킷이 생성된다.

2. Pod1 에서 라우팅 테이블을 확인하고 기본 라우팅 테이블이 169.254.1.1인 것을 확인한다.

3. Pod1 안에서 169.254.1.1의 MAC주소를 알아내기 위해 ARP 요청을 브로드캐스트한다. 해당 요청은 Pod의 veth 인터페이스(eth0@if6)를 통해서 Node로 전달된다.

4. Node에서 실행 중인 Calico CNI 프로세스가 해당 ARP 요청을 감지하고, Calico CNI는 가상의 MAC 주소( ee:ee:ee:ee:ee:ee)로 ARP 응답을 생성해 Pod1로 전달한다.


5. Pod1은 ICMP 패킷을 생성하고 Pod2의 IP(172.16.158.2)에 대한 패킷을 구성하고 다음 홉(ee:ee:ee:ee:ee:ee)으로 목적지를 설정해 전달한다. 해당 패킷은 veth 쌍(Pod의 eth0@if6 --- Node의 calice0906292e2@if3)을 통해서 Node로 전달된다.

6. Node의 veth 인터페이스(calice0906292e2@if3)가 패킷을 수신하고, Node의 네트워크 스택에서 패킷을 처리한다. Node는 자체 라우팅과 Calico CNI에 의해 설정된 라우팅 테이블을 확인하고, Pod2로 가는 경로가 Node 안에 있음을 확인한다.

7. Node는 172.16.158.2에 해당하는 MAC 주소를 알아내기 위해 ARP요청을 브로드캐스트한다. 해당 요청은 Node의 인터페이스에 모두 전달된다.

8. Pod2에 연결된 veth 인터페이스(calibd2348b4f67@if3)를 통해 Calico CNI 프로세스에서 이를 감지하고 Pod2의 MAC 주소로 ARP 응답을 Node로 전달한다.

9. Node는 수신한 Pod2의 MAC 주소를 업데이트하고 라우팅 테이블에 따라서 Pod2의 veth(calibd2348b4f67@if3)로 전달한다.
10. Pod2는 ICMP echo request를 수신하고 처리한다.
11. Pod2는 ICMP echo reply 패킷을 생성하여 Pod1(172.16.158.1)로 응답을 보낸다.
이후는 2~6번의 과정이 Pod2에서 Pod1로 유사하게 처리된다. Node에서 ICMP 응답 패킷을 네트워크 스택에서 처리하고 Pod1번의 veth 인터페이스로 전달하고 Pod1번에서는 ICMP echo reply를 수신하고 처리한다.
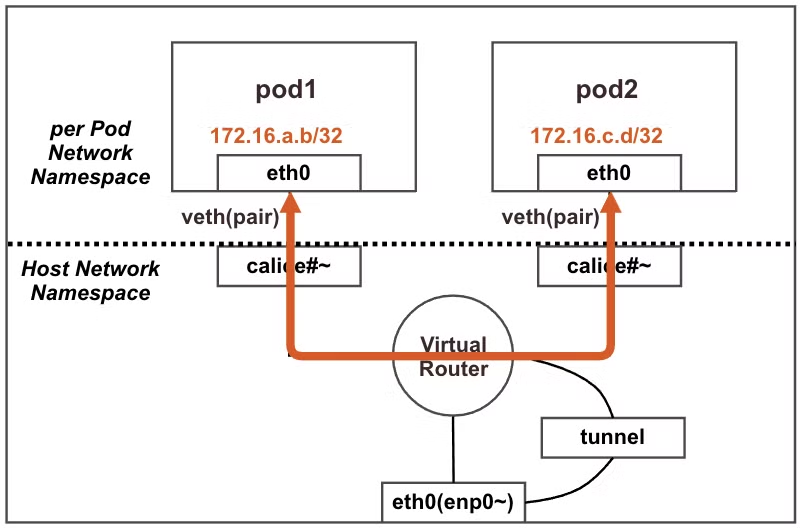
통신 흐름도
상세하게 하나하나 찾아봤는데 패킷의 흐름은 아래의 그림과 같이 수행된다.
여기서 핵심은 같은 Node에서의 Pod간의 통신은 tunnel을 통하지 않고 내부에서 직접 통신된다는 것이다.
참고자료
- Benchmark results of Kubernetes network plugins (CNI) over 40Gbit/s network [2024] : https://itnext.io/benchmark-results-of-kubernetes-network-plugins-cni-over-40gbit-s-network-2024-156f085a5e4e#89d8-90c23c8caeb4-reply
- K9S : https://github.com/derailed/k9s
- K9S 설치 및 사용법 : https://peterica.tistory.com/276
- https://learnk8s.io/kubernetes-network-packets
컨테이너에 대한 사전 정보를 알아봤으니, 실제 K8S(Kubernetes)에서의 네트워크를 알아보자.
스터디를 위한 구성
스터디를 위한 K8S 구성은 AWS에 구성하였으며, 아래와 같다.
root@k8s-m:~# kubectl get node -owide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-m NotReady control-plane 57s v1.30.5 192.168.10.10 <none> Ubuntu 22.04.5 LTS 6.5.0-1024-aws containerd://1.7.22
k8s-w0 NotReady <none> 37s v1.30.5 192.168.20.100 <none> Ubuntu 22.04.5 LTS 6.5.0-1024-aws containerd://1.7.22
k8s-w1 NotReady <none> 35s v1.30.5 192.168.10.101 <none> Ubuntu 22.04.5 LTS 6.5.0-1024-aws containerd://1.7.22
k8s-w2 NotReady <none> 37s v1.30.5 192.168.10.102 <none> Ubuntu 22.04.5 LTS 6.5.0-1024-aws containerd://1.7.22
root@k8s-m:~# calicoctl version
Client Version: v3.28.1
Git commit: 601856343
Cluster Version: v3.28.1
Cluster Type: k8s,bgp,kubeadm,kdd- K8S v1.30
- Nodes
- OS(Ubuntu 22.04 LTS)
- 2개의 다른 서브넷 구성 : 192.168.10.0/24 대역과 192.168.20.0/24 대역
- CNI(Calico v3.28.1, IPIP, NAT enable)
- IPTABLES proxy mode
CNI란?
"Container Network Interface"로 컨테이너 환경에서 네트워크 인터페이스를 설정하고 관리하기 위한 표준 인터페이스이다. K8S의 네트워크 요구사항을 만족하기 위한 일종의 규칙이라고 볼 수 있다.
이런 CNI에 대한 상세 스펙은 아래의 문서에서 확인할 수 있다.
CNI가 없다면, 라우팅 구성, eth 장치 구성, IP할당, 네트워크 네임스페이스 구성 등을 Pod가 생성되고 삭제될 때마다 수동으로 해줘야한다.
CNI 플러그인
이러한 인터페이스를 만족시키는 프로그램을 CNI 플러그인이라고 하며 다양한 종류가 있다.
- Calico : https://www.tigera.io/project-calico/
- Cillium : https://cilium.io/
Flannel : https://github.com/flannel-io/flannel - 그 외 다양한 CNI 플러그인 : https://github.com/containernetworking/cni#3rd-party-plugins
각 CNI 플러그인 별로 장단점이 있으므로 관심이 있다면 아래 링크를 통해서 어떤 점이 내 K8S 구성에 적절한지 보고 선택하면 좋을 것이다.
Benchmark results of Kubernetes network plugins (CNI) over 40Gbit/s network [2024]
This article is a new run of my previous benchmark (2020, 2019 and 2018), now running Kubernetes 1.26 and Ubuntu 22.04 with CNI version…
itnext.io
CNI 플러그인 주요 역할
CNI에서는 아래에 명시된 6가지 주요 동작을 지원한다.
https://github.com/containernetworking/cni/blob/main/SPEC.md#cni-operations
- ADD 작업 : 컨테이너를 네트워크에 추가하거나, 기존 네트워크 설정을 수정하는 작업
- DEL 작업 : 네트워크에서 컨테이너를 제거하거나, 이전에 적용된 네트워크 설정을 해제하는 작업
- CHECK 작업 : 기존 컨테이너의 네트워크 상태가 예상대로인지 확인하는 작업
- STATUS 작업 : 네트워크 플러그인이 ADD 요청을 처리할 준비가 되어 있는지 확인하는 작업
- VERSION 작업 : 플러그인이 지원하는 버전 정보를 반환하는 작업
- GC(Garbage Collection) 작업 : 사용되지 않는 네트워크 리소스를 정리하는 작업
(추가) 나중에 더 파보기
따로 좀 찾아보다가 재밌는 글을 찾았는데 bash script로 해당 CNI 플러그인을 만드는 글이었다.
테스트를 좀 해보다가 해당 글 작성이 밀려서 나중으로 미뤘는데, 현재 버전에 맞게 테스트를 해보면 Pod간 통신을 이해하기 더 좋을 것 같다.
이번 스터디에서는 Calico를 사용해서 네트워크를 확인해본다.
Pod 배포 전 초기 구성 확인
CNI 동작을 확인해보기 위해 현재 초기 구성을 확인해본다.
Pod 배포는 1번 노드에서 수행할 예정이므로 1번 노드에서 확인한다.
# tunl0가 생성되어있고, 172.16.158.0/32를 할당받음
root@k8s-w1:~# ip -c -d addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 promiscuity 0 minmtu 0 maxmtu 0 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
...
2: ens5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
link/ether 02:f4:40:5c:3d:8b brd ff:ff:ff:ff:ff:ff promiscuity 0 minmtu 128 maxmtu 9216 numtxqueues 2 numrxqueues 2 gso_max_size 65536 gso_max_segs 65535 parentbus pci parentdev 0000:00:05.0
altname enp0s5
inet 192.168.10.101/24 metric 100 brd 192.168.10.255 scope global dynamic ens5
valid_lft 3498sec preferred_lft 3498sec
...
3: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 8981 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0 promiscuity 0 minmtu 0 maxmtu 0
ipip any remote any local any ttl inherit nopmtudisc numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
inet 172.16.158.0/32 scope global tunl0
valid_lft forever preferred_lft forever
# node에서는 root 네임스페이스를 사용
root@k8s-w1:~# lsns -t net
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531840 net 131 1 root unassigned
root@k8s-w1:~# ip -c route | sort
172.16.116.0/24 via 192.168.10.10 dev tunl0 proto bird onlink
172.16.184.0/24 via 192.168.10.102 dev tunl0 proto bird onlink
172.16.34.0/24 via 192.168.20.100 dev tunl0 proto bird onlink
192.168.0.2 via 192.168.10.1 dev ens5 proto dhcp src 192.168.10.101 metric 100
192.168.10.0/24 dev ens5 proto kernel scope link src 192.168.10.101 metric 100
192.168.10.1 dev ens5 proto dhcp scope link src 192.168.10.101 metric 100
blackhole 172.16.158.0/24 proto bird
default via 192.168.10.1 dev ens5 proto dhcp src 192.168.10.101 metric 100
여기서 주의 깊게 볼 것은 bird로 표시된 라우팅인데, bird는 각 노드마다 존재하는 BGP 데몬이다.
이 bird 데몬은 다른 노드에 있는 데몬들과 라우팅 정보를 교환하는데, 여기서 bird로 표시된 대역대는 각 노드에서 관리하는 Pod의 네트워크 대역이다.
또 bird로 표시된 blackhole도 확인할 수 있는데, 해당 blackhole은 쓸모없어진 통신 패킷을 삭제하는데 사용된다.
단순하게 예를 들어서 설명하면 2개의 Pod A,B가 서로 통신을 수행하다 B Pod가 삭제되었다고 가정해보자. 이 때 A Pod에서 보낸 패킷은 라우팅에 의해서 B Pod가 있던 노드(혹은 터널)로 이동하고 해당 노드(혹은 터널)에서는 더 이상 존재하지 않는 IP에 대한 패킷이므로 최상위 매핑 규칙에 의해 default gateway로 전송되는 사례가 발생할 수 있다. 이런 경우 불필요한 패킷이 떠다니며 트래픽을 발생시키므로 삭제하기 위해 blackhole 라우팅이 사용된다.
조금 더 자세히 이해하고 싶으면 해당 github issue 토론을 보면 왜 blackhole 대역이 필요한지 등을 볼 수 있다.
같은 Node 내에서 Pod 간의 통신
하나의 Node에 Pod 2개를 배포하고 통신을 확인해보자.
# 출처 : https://github.com/gasida/NDKS
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
nodeName: k8s-w1
containers:
- name: pod1
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
---
apiVersion: v1
kind: Pod
metadata:
name: pod2
spec:
nodeName: k8s-w1
containers:
- name: pod2
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
curl -s -O https://raw.githubusercontent.com/gasida/NDKS/main/4/node1-pod2.yaml
kubectl apply -f node1-pod2.yamlroot@k8s-m:~# calicoctl get workloadendpoints
WORKLOAD NODE NETWORKS INTERFACE
pod1 k8s-w1 172.16.158.1/32 calice0906292e2
pod2 k8s-w1 172.16.158.2/32 calibd2348b4f671번 노드에서 Pod가 생성되고 초기 상태와 비교해보자.
root@k8s-w1:~# ip -c -d addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
...
2: ens5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
link/ether 02:f4:40:5c:3d:8b brd ff:ff:ff:ff:ff:ff promiscuity 0 minmtu 128 maxmtu 9216 numtxqueues 2 numrxqueues 2 gso_max_size 65536 gso_max_segs 65535 parentbus pci parentdev 0000:00:05.0
...
3: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 8981 qdisc noqueue state UNKNOWN group default qlen 1000
...
6: calice0906292e2@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8981 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-fe3f61e6-ddc0-89b3-109f-e970404aeaf1 promiscuity 0 minmtu 68 maxmtu 65535
veth numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
7: calibd2348b4f67@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8981 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-dbbe8c16-9d9c-41fb-967b-7a1b8224b510 promiscuity 0 minmtu 68 maxmtu 65535
veth numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
root@k8s-w1:~# lsns -t net
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531840 net 131 1 root unassigned /sbin/init
4026532218 net 2 28053 65535 0 /run/netns/cni-fe3f61e6-ddc0-89b3-109f-e970404aeaf1 /pause
4026532277 net 2 28077 65535 1 /run/netns/cni-dbbe8c16-9d9c-41fb-967b-7a1b8224b510 /pause
root@k8s-w1:~# ip -c route | sort
172.16.116.0/24 via 192.168.10.10 dev tunl0 proto bird onlink
172.16.158.1 dev calice0906292e2 scope link
172.16.158.2 dev calibd2348b4f67 scope link
172.16.184.0/24 via 192.168.10.102 dev tunl0 proto bird onlink
172.16.34.0/24 via 192.168.20.100 dev tunl0 proto bird onlink
192.168.0.2 via 192.168.10.1 dev ens5 proto dhcp src 192.168.10.101 metric 100
192.168.10.0/24 dev ens5 proto kernel scope link src 192.168.10.101 metric 100
192.168.10.1 dev ens5 proto dhcp scope link src 192.168.10.101 metric 100
blackhole 172.16.158.0/24 proto bird
default via 192.168.10.1 dev ens5 proto dhcp src 192.168.10.101 metric 1001번 노드에 새로운 장치 2개가 생성되었고, 네트워크 네임스페이스도 2개가 새로 생성되었다. 라우팅 테이블도 2개가 새로 추가된 것을 볼 수 있다.
각 Pod에 접속해서 네트워크 장치와 라우팅을 확인해보자.
희안한게 eth0@if6, eth0@if7 장치에 Pod IP가 할당되어있고, 2개의 Pod 모두 라우팅 테이블이 기본으로 169.254.1.1로 잡혀있다. 이런 상황에서 Pod 간에 통신이 될까?
ping이 잘 간다. ARP 테이블을 확인해보면 169.254.1.1로 MAC주소가 잘 등록되어있다.
어떻게 통신하는 걸까? tcpdump를 통해 상세히 확인해보자.
Pod간 통신 상세 분석
Calico CNI가 생성해준 네트워크 인터페이스를 통해 상세하게 알아보자.
(주의) 이 부분은 스터디 자료를 기반으로 한 테스트와 검색을 통해서 하나씩 찾아보면서 이해한 내용이라 다소 잘못된 내용이 있을 수 있으니 잘못된 내용은 공유 부탁드립니다.
# control-plane 노드에서 수행
root@k8s-m:~# calicoctl get workloadEndpoint
WORKLOAD NODE NETWORKS INTERFACE
pod1 k8s-w1 172.16.158.1/32 calice0906292e2
pod2 k8s-w1 172.16.158.2/32 calibd2348b4f67
# 1번 노드에서 수행
for file in /proc/sys/net/ipv4/conf/*/proxy_arp; do
ls -l $file | tr -s ' ' | cut -d' ' -f1-8 | tr '\n' ' '
echo -n "$file "
cat $file
done
-rw-r--r-- 1 root root 0 Sep 22 00:51 /proc/sys/net/ipv4/conf/all/proxy_arp 0
-rw-r--r-- 1 root root 0 Sep 21 23:54 /proc/sys/net/ipv4/conf/calibd2348b4f67/proxy_arp 1
-rw-r--r-- 1 root root 0 Sep 21 23:54 /proc/sys/net/ipv4/conf/calice0906292e2/proxy_arp 1
-rw-r--r-- 1 root root 0 Sep 22 00:51 /proc/sys/net/ipv4/conf/default/proxy_arp 0
-rw-r--r-- 1 root root 0 Sep 22 00:51 /proc/sys/net/ipv4/conf/ens5/proxy_arp 0
-rw-r--r-- 1 root root 0 Sep 22 00:51 /proc/sys/net/ipv4/conf/lo/proxy_arp 0
-rw-r--r-- 1 root root 0 Sep 22 00:51 /proc/sys/net/ipv4/conf/tunl0/proxy_arp 0
VETH1=calice0906292e2
tcpdump -i $VETH1 -nn
# tcpdump 후 1번 Pod에서 2번 Pod로 Ping 수행
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on calice0906292e2, link-type EN10MB (Ethernet), snapshot length 262144 bytes
...
01:15:00.108534 ARP, Request who-has 169.254.1.1 tell 172.16.158.1, length 28
01:15:00.108573 ARP, Reply 169.254.1.1 is-at ee:ee:ee:ee:ee:ee, length 28
01:15:00.108578 IP 172.16.158.1 > 172.16.158.2: ICMP echo request, id 77, seq 1, length 64
...
01:15:05.230514 IP 172.16.158.2 > 172.16.158.1: ICMP echo reply, id 77, seq 6, length 64
01:15:05.294411 ARP, Request who-has 172.16.158.1 tell 192.168.10.101, length 28
01:15:05.294459 ARP, Reply 172.16.158.1 is-at 86:e5:22:07:c3:f3, length 28
01:15:06.254448 IP 172.16.158.1 > 172.16.158.2: ICMP echo request, id 77, seq 7, lenARP 패킷을 통해 169.254.1.1이라는 IP가 172.16.158.1이라고 확인하고, 1번 Pod의 IP(172.16.158.1)가 192.168.10.101이라고 확인한다.
위의 통신 과정을 이해하려면 2가지를 이해해야 한다.
Proxy ARP 란?
ARP의 확장 기능으로 한 네트워크 호스트가 다른 호스트를 대신해서 ARP 요청에 응답할 수 있게 해주는 기능이다.
아까 proxy_arp 설정이 1로 되어있는 것을 확인했는데, 이 설정을 통해서 Node가 Pod의 IP 주소에 대한 ARP 요청에 대신 응답을 해줄 수 있는 것이다. 조금 더 자세히 설명하면 proxy_arp는 인터페이스가 다른 네트워크의 ARP 요청에 대해 대신 응답할 수 있게 해주는 Linux 커널 기능이다.
-rw-r--r-- 1 root root 0 Sep 21 23:54 /proc/sys/net/ipv4/conf/calibd2348b4f67/proxy_arp 1
-rw-r--r-- 1 root root 0 Sep 21 23:54 /proc/sys/net/ipv4/conf/calice0906292e2/proxy_arp 1따라서 이 설정을 0으로 바꾸면 당연하게도 잘되던 Pod 간의 통신은 막혀버린다.
(여러번 pod를 생성하고 삭제하다보니 IP가 변경되었는데, 172.16.158.6이 기존 Pod1번 172.16.158.1이다.)
위의 tcpdump에서 Pod1번(172.16.158.1)은 ping을 수행하기 위해 169.254.1.1의 MAC주소를 찾으려고 하고, Node에서는 Proxy ARP를 통해 ee:ee:ee:ee:ee:ee라고 응답한다. (더 정확하게는 Calico CNI의 veth에서 응답해주는 것으로 보인다.)
In some setups the kernel is unable to generate a persistent MAC address and so Calico assigns a MAC address itself. Since Calico uses point-to-point routed interfaces, traffic does not reach the data link layer so the MAC Address is never used and can therefore be the same for all the cali* interfaces.
스터디에서 알게된 내용으로 일부 커널이 고정 맥 주소 생성이 안되서, Calico가 자체 MAC을 생성한다고 한다.
또한 파드와 cali#(veth pair) 는 point-to-point routed interfaces 를 사용하기 때문에 호스트의 데이터링크 레이어(L2 Layer) 에 도달하지 않아서, 모든 cali# 가 동일한 맥 주소를 사용해도 문제가 없다고 한다.
169.254.1.1는 어떤 IP인가?
169.254.0.0/16 범위의 IP 주소는 link-local address라고 하는 예약된 IP 주소이다.
해당 대역의 IP는 IANA (Internet Assigned Numbers Authority)에 의해 특별한 용도로 예약되어있어, 일반적인 인터넷 통신에 사용되지 않는다.
용도는 다양한데, 쉽게 볼 수 있는 경우는 Windows 시스템에서 이 범위를 APIPA (Automatic Private IP Addressing)로 사용해 DHCP가 동작하지 않을 경우 임의로 할당해 사용하기도 한다.
Calico CNI에서는 Pod의 기본 게이트웨이로 설정해 특별하게 사용한다.
Calico tries hard to avoid interfering with any other configuration on the host. Rather than adding the gateway address to the host side of each workload interface, Calico sets the
proxy_arp
flag on the interface. This makes the host behave like a gateway, responding to ARPs for 169.254.1.1 without having to actually allocate the IP address to the interface.
Ping이 수행되는 과정
이제 그럼 어떻게 같은 Node 내에서 서로 다른 Pod간에 통신이 수행되는지 하나씩 보자.
1. Pod1(172.16.158.1)에서 Ping 명령을 수행해 Pod2(172.16.158.2)로의 ICMP echo Request 패킷이 생성된다.
2. Pod1 에서 라우팅 테이블을 확인하고 기본 라우팅 테이블이 169.254.1.1인 것을 확인한다.
3. Pod1 안에서 169.254.1.1의 MAC주소를 알아내기 위해 ARP 요청을 브로드캐스트한다. 해당 요청은 Pod의 veth 인터페이스(eth0@if6)를 통해서 Node로 전달된다.
4. Node에서 실행 중인 Calico CNI 프로세스가 해당 ARP 요청을 감지하고, Calico CNI는 가상의 MAC 주소( ee:ee:ee:ee:ee:ee)로 ARP 응답을 생성해 Pod1로 전달한다.
5. Pod1은 ICMP 패킷을 생성하고 Pod2의 IP(172.16.158.2)에 대한 패킷을 구성하고 다음 홉(ee:ee:ee:ee:ee:ee)으로 목적지를 설정해 전달한다. 해당 패킷은 veth 쌍(Pod의 eth0@if6 --- Node의 calice0906292e2@if3)을 통해서 Node로 전달된다.
6. Node의 veth 인터페이스(calice0906292e2@if3)가 패킷을 수신하고, Node의 네트워크 스택에서 패킷을 처리한다. Node는 자체 라우팅과 Calico CNI에 의해 설정된 라우팅 테이블을 확인하고, Pod2로 가는 경로가 Node 안에 있음을 확인한다.
7. Node는 172.16.158.2에 해당하는 MAC 주소를 알아내기 위해 ARP요청을 브로드캐스트한다. 해당 요청은 Node의 인터페이스에 모두 전달된다.
8. Pod2에 연결된 veth 인터페이스(calibd2348b4f67@if3)를 통해 Calico CNI 프로세스에서 이를 감지하고 Pod2의 MAC 주소로 ARP 응답을 Node로 전달한다.
9. Node는 수신한 Pod2의 MAC 주소를 업데이트하고 라우팅 테이블에 따라서 Pod2의 veth(calibd2348b4f67@if3)로 전달한다.
10. Pod2는 ICMP echo request를 수신하고 처리한다.
11. Pod2는 ICMP echo reply 패킷을 생성하여 Pod1(172.16.158.1)로 응답을 보낸다.
이후는 2~6번의 과정이 Pod2에서 Pod1로 유사하게 처리된다. Node에서 ICMP 응답 패킷을 네트워크 스택에서 처리하고 Pod1번의 veth 인터페이스로 전달하고 Pod1번에서는 ICMP echo reply를 수신하고 처리한다.
통신 흐름도
상세하게 하나하나 찾아봤는데 패킷의 흐름은 아래의 그림과 같이 수행된다.
여기서 핵심은 같은 Node에서의 Pod간의 통신은 tunnel을 통하지 않고 내부에서 직접 통신된다는 것이다.
참고자료
- Benchmark results of Kubernetes network plugins (CNI) over 40Gbit/s network [2024] : https://itnext.io/benchmark-results-of-kubernetes-network-plugins-cni-over-40gbit-s-network-2024-156f085a5e4e#89d8-90c23c8caeb4-reply
- K9S : https://github.com/derailed/k9s
- K9S 설치 및 사용법 : https://peterica.tistory.com/276
- https://learnk8s.io/kubernetes-network-packets