
[24단계 실습으로 정복하는 쿠버네티스] 책으로 스터디를 진행하였다.
Prometheus란?
Prometheus는 시스템과 서비스를 모니터링하기 위한 도구로, Pull 방식의 모니터링 시스템과 경보 알람을 제공한다.
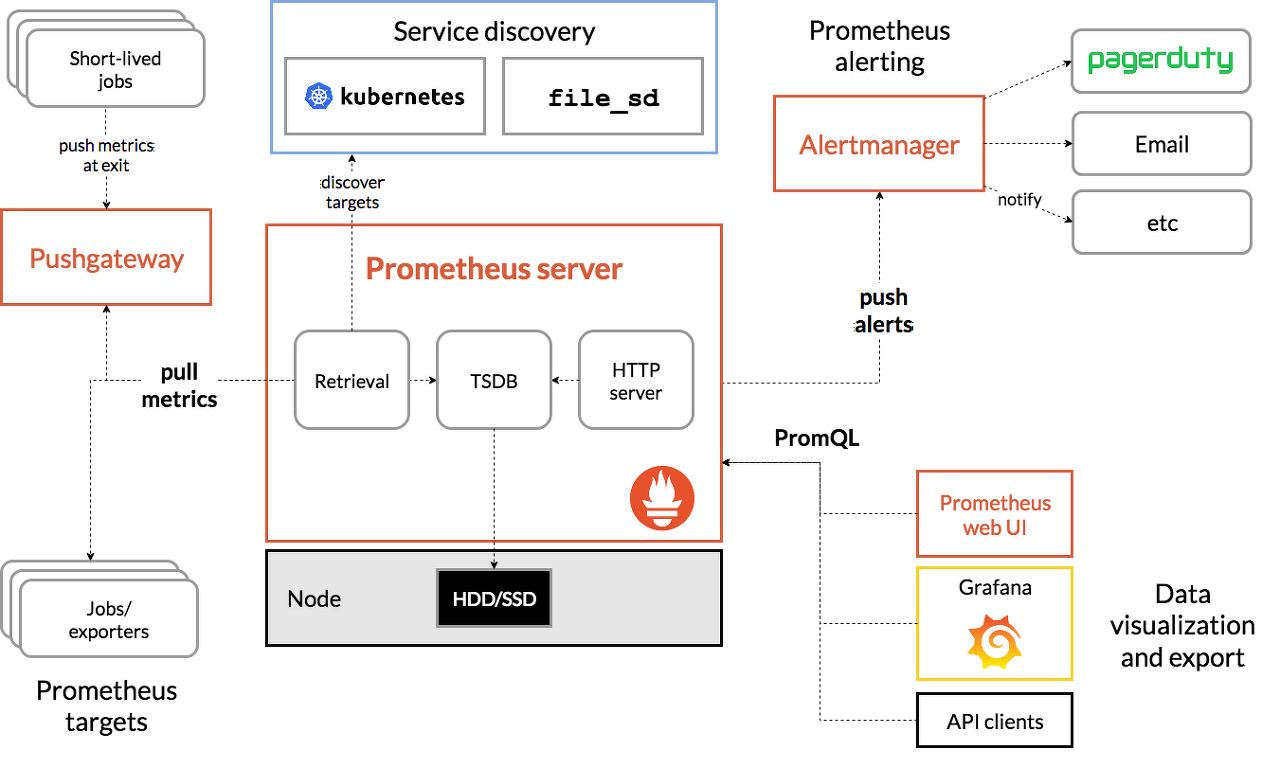
모니터링할 대상에 exproter라는 Agent가 설치되고 해당 Agent에서 다양한 모니터링 정보(Metric)을 수집해 놓으면 Prometheus Server에서 해당 데이터를 가져가는 방식을 취한다.
- 일반적으로는 Pull 방식을 취해 데이터를 수집하지만, Pushgateway를 통해서 짧은 수명의 작업(어플리케이션 등)은 Push 방식을 지원하는 것으로 확인된다.
- PromQL(Prometheus Query Language)이라는 질의언어를 제공한다. (일반적인 SQL은 아니지만 함수 등을 제공해 직관적이다.)
- 다양한 형태의 그래프를 제공하지만, Prometheus 자체로 제공하는 그래프는 다소 보기 어려워 Grafana라는 시각화 도구를 같이 사용한다.
Grafana란?
다양한 TSDB(Time Series DataBase)의 데이터(Metric, Log)를 보기편하게 시각화해주는 도구로, 시각화된 다양한 그래프와 경보 알람을 제공한다.
Prometheus & Grafana 구축
Kubernetes Operateor로 Helm을 통해 kube-prometheus-stack(Prometheus & Grafana 포함된 stack)을 비교적 간단히 설치할 수 있다.
kube-prometheus-stack 설치
// kube-prometheus-stack Chart 저장소 추가 및 최신화
(ersia:default) [root@kops-ec2 ~]# helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
"prometheus-community" has been added to your repositories
(ersia:default) [root@kops-ec2 ~]# helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "prometheus-community" chart repository
Update Complete. ⎈Happy Helming!⎈
// 추가 설정을 위해 로컬에 kube-prometheus-stack Chart 다운로드
(ersia:default) [root@kops-ec2 ~]# helm fetch prometheus-community/kube-prometheus-stack --untar
(ersia:default) [root@kops-ec2 ~]# tree kube-prometheus-stack -L 1
kube-prometheus-stack
├── Chart.lock
├── charts
├── Chart.yaml
├── CONTRIBUTING.md
├── crds
├── README.md
├── templates
└── values.yaml
3 directories, 5 files
// 아래의 내용을 수정
(ersia:default) [root@kops-ec2 ~]# vim ~/kube-prometheus-stack/values.yaml
140 alertmanager:
260 ingress:
261 enabled: true ## alertmanager의 ingress 사용
265 ingressClassName: alb ## ingressClasss는 alb로 사전 생성 후 통일해 사용
267 annotations: ## alb 관련 인증서 및 상세 설정
268 alb.ingress.kubernetes.io/scheme: internet-facing
269 alb.ingress.kubernetes.io/target-type: ip
270 alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
271 alb.ingress.kubernetes.io/certificate-arn: '{certificate-arn}' ## AWS인증서를 사용하기 위해 인증서의 ARN으로 입력
272 alb.ingress.kubernetes.io/success-codes: 200-399
273 alb.ingress.kubernetes.io/group.name: "monitoring" ## alertmanager, grafana, prometheus 모두 하나의 ingress Controller를 사용하기 위한 group설정
282 hosts:
283 - alertmanager.ersia.net ## alertmanger의 host 도메인
287 paths: ## alertmanger의 도메인 연결 시 path 사용 여부
288 - /* ## alertmanager, grafana, prometheus 모두 host 도메인으로 분리하므로 '/' Path 사용
756 grafana:
775 defaultDashboardsTimezone: Asia/Seoul ## Grafana의 기본 Timezone, 기본값은 utc
777 adminPassword: prom-operator ## Grafana의 웹 접속 시 초기 패스워드
784 ingress:
787 enabled: true ## grafana도 ingress를 사용할 예정이므로 true로 변경
792 ingressClassName: alb ## ingressClasss는 alb로 사전 생성 후 통일해 사용
796 annotations: ## alb 관련 인증서 및 상세 설정
797 alb.ingress.kubernetes.io/scheme: internet-facing
798 alb.ingress.kubernetes.io/target-type: ip
799 alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
800 alb.ingress.kubernetes.io/certificate-arn: '{certificate-arn}'
801 alb.ingress.kubernetes.io/success-codes: 200-399
802 alb.ingress.kubernetes.io/group.name: "monitoring"
813 hosts: ## grafana의 host 도메인
814 - grafana.ersia.net
817 paths: ## grafana 도메인 연결 시 path 사용 여부
818 - /*
2235 prometheus:
2492 ingress:
2493 enabled: true ## prometheus도 ingress를 사용할 예정이므로 true로 변경
2497 ingressClassName: alb
2499 annotations:
2500 alb.ingress.kubernetes.io/scheme: internet-facing
2501 alb.ingress.kubernetes.io/target-type: ip
2502 alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
2503 alb.ingress.kubernetes.io/certificate-arn: '{certificate-arn}'
2504 alb.ingress.kubernetes.io/success-codes: 200-399
2505 alb.ingress.kubernetes.io/group.name: "monitoring"
2516 hosts: ## prometheus의 host 도메인
2517 - prometheus.ersia.net
2521 paths: ## prometheus 도메인 연결 시 path 사용 여부
2522 - /*
2642 prometheusSpec: ## 참고 : https://stackoverflow.com/questions/68085831/add-podmonitor-or-servicemonitor-outside-of-kube-prometheus-stack-helm-values
2824 serviceMonitorSelectorNilUsesHelmValues: false ## 별도의 service,pod monitor를 사용할지 여부
2847 podMonitorSelectorNilUsesHelmValues: false ## false로 설정 후 제공하는 service,pod monitor를 통해 자동으로 prometheus target이 추가됨
2885 retention: 10d ## Metric 보관 주기, 10일이 지난 데이터는 주기적으로 삭제
2889 retentionSize: "10GiB" ## 데이터 저장을 위한 디스크 최대 사이즈, 10GiB가 되면 가장 오래된 데이터부터 삭제
// 모니터링용 Namespace 생성
(ersia:default) [root@kops-ec2 ~]# kubectl create ns monitoring
namespace/monitoring created
// 수정한 helm chart로 kube-prometheus-stack 설치
## 설치 시 command로 옵션을 추가로 입력할 수 있다.
## scrape_interval: 15s # 15초마다 metric을 수집한다. 기본값은 60초.
## evaluation_interval: 15s # 15초마다 설정된 경보를 보낼지 규칙을 확인하는 주기이다. 기본값은 60초.
(ersia:default) [root@kops-ec2 ~]# helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.8.1 \
> --set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
> -f ~/kube-prometheus-stack/values.yaml --namespace monitoring
NAME: kube-prometheus-stack
LAST DEPLOYED: Sun Apr 2 01:57:33 2023
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace monitoring get pods -l "release=kube-prometheus-stack"
Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
// 정상 설치 확인
(ersia:default) [root@kops-ec2 ~]# helm list -n monitoring
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kube-prometheus-stack monitoring 1 2023-04-02 01:57:33.124167646 +0900 KST deployed kube-prometheus-stack-45.8.1 v0.63.0
(ersia:default) [root@kops-ec2 ~]# kubectl get pod,svc,ingress -n monitoring
NAME READY STATUS RESTARTS AGE
pod/alertmanager-kube-prometheus-stack-alertmanager-0 2/2 Running 1 (77s ago) 83s
pod/kube-prometheus-stack-grafana-8fc98f79-8pzbz 3/3 Running 0 90s
pod/kube-prometheus-stack-kube-state-metrics-66566bbbf-s65dn 1/1 Running 0 90s
pod/kube-prometheus-stack-operator-85857b9b68-j86d5 1/1 Running 0 90s
pod/kube-prometheus-stack-prometheus-node-exporter-2gwrm 1/1 Running 0 90s
pod/kube-prometheus-stack-prometheus-node-exporter-cp2lc 1/1 Running 0 90s
pod/kube-prometheus-stack-prometheus-node-exporter-n58j8 1/1 Running 0 90s
pod/prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 83s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 83s
service/kube-prometheus-stack-alertmanager ClusterIP 100.71.251.83 <none> 9093/TCP 90s
service/kube-prometheus-stack-grafana ClusterIP 100.66.173.8 <none> 80/TCP 90s
service/kube-prometheus-stack-kube-state-metrics ClusterIP 100.68.195.189 <none> 8080/TCP 90s
service/kube-prometheus-stack-operator ClusterIP 100.68.249.133 <none> 443/TCP 90s
service/kube-prometheus-stack-prometheus ClusterIP 100.68.245.242 <none> 9090/TCP 90s
service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 100.69.159.29 <none> 9100/TCP 90s
service/prometheus-operated ClusterIP None <none> 9090/TCP 83s
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress.networking.k8s.io/kube-prometheus-stack-alertmanager alb alertmanager.ersia.net k8s-monitoring-b219e55b0b-1120834911.ap-northeast-2.elb.amazonaws.com 80 90s
ingress.networking.k8s.io/kube-prometheus-stack-grafana alb grafana.ersia.net 80 90s
ingress.networking.k8s.io/kube-prometheus-stack-prometheus alb prometheus.ersia.net 80 90shttps://artifacthub.io/packages/helm/prometheus-community/kube-prometheus-stack#install-helm-chart
Node의 사양이 낮으면(c5a.large 기준) TargetGroup 활성화까지 5분 가량 소요되는 것으로 보인다.
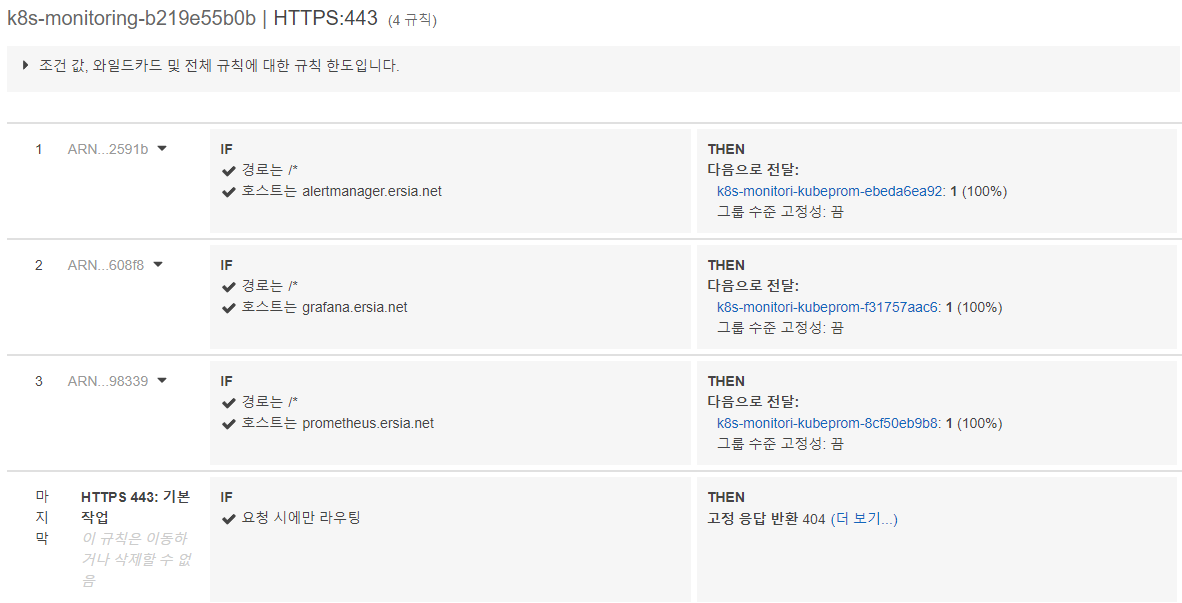
정상적으로 설치가 완료되면 Ingress Controller(ALB) 1개가 생성된 것과 설정한 hostname이 ALB 규칙에 host로 입력된 것을 확인할 수 있다.
(ersia:default) [root@kops-ec2 ~]# kubectl get ingress -n monitoring
NAME CLASS HOSTS ADDRESS PORTS AGE
kube-prometheus-stack-alertmanager alb alertmanager.ersia.net k8s-monitoring-b219e55b0b-196433738.ap-northeast-2.elb.amazonaws.com 80 2m19s
kube-prometheus-stack-grafana alb grafana.ersia.net k8s-monitoring-b219e55b0b-196433738.ap-northeast-2.elb.amazonaws.com 80 2m19s
kube-prometheus-stack-prometheus alb prometheus.ersia.net k8s-monitoring-b219e55b0b-196433738.ap-northeast-2.elb.amazonaws.com 80 2m19s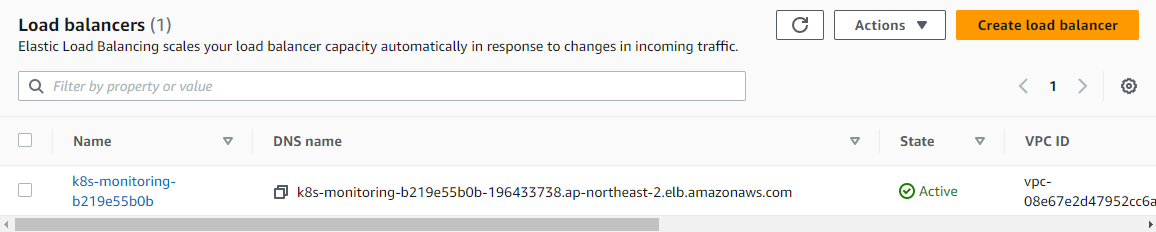
kube-prometheus-stack 설치 후 Promethus 웹페이지 접속
설치 시 입력한 host URL로 접속하면 로그인 가능한 웹페이지를 확인할 수 있다. (예시 : promethus.ersia.net)
promethus에는 별도의 인증없이 접속 가능하다.
kube-prometheus-stack로 설치하면 promethus 단독 설치와는 다르게 기본적인 rule이나 alert 설정이 되어있다.
- Alerts : Promethus에서 확인된 경보 목록(알람 발생/미발생/보류 포함)을 조회할 수 있다, 현재까지 진행된 설정으로 설치 시 4개 가량의 Alert가 발생해있다.
- Graph : PromQL을 사용해 수집된 메트릭 정보를 조회할 수 있다.
- Status : Promethus 설정, Alert 규칙 설정 및 조회, 모니터링 대상 확인 등의 정보를 확인할 수 있다.
필수 기능은 모두 제공되지만 시각화나 그래프 형태로 조회하기엔 조금 어려움이 있는데,
이런 그래프와 시각화를 Grafana를 통해 해결할 수 있다.
Grafana 웹페이지 접속
설치 시 입력한 host URL로 접속하면 로그인 가능한 웹페이지를 확인할 수 있다. (예시 : grafana.ersia.net)
초기 로그인 정보는 admin / 설치시 정의한 초기 패스워드(prom-operator)이다.

로그인 후 맨 왼쪽 하단의 Configuration > Data Sources > 에서 Data Source를 추가해 데이터 시각화를 사용할 수 있으며,
kube-prometheus-stack로 설치하면 기본값으로 Prometheus를 자동 설정해준다.
맨 왼쪽 상단의 Dashboards > Browse 에서 추가한 Data Sources를 Dashboard로 다양한 시각화 그래프를 제공하는데,
초기 설정에서는 기본적인 Kubernetes 정보에 대한 Dashboard를 확인할 수 있다.
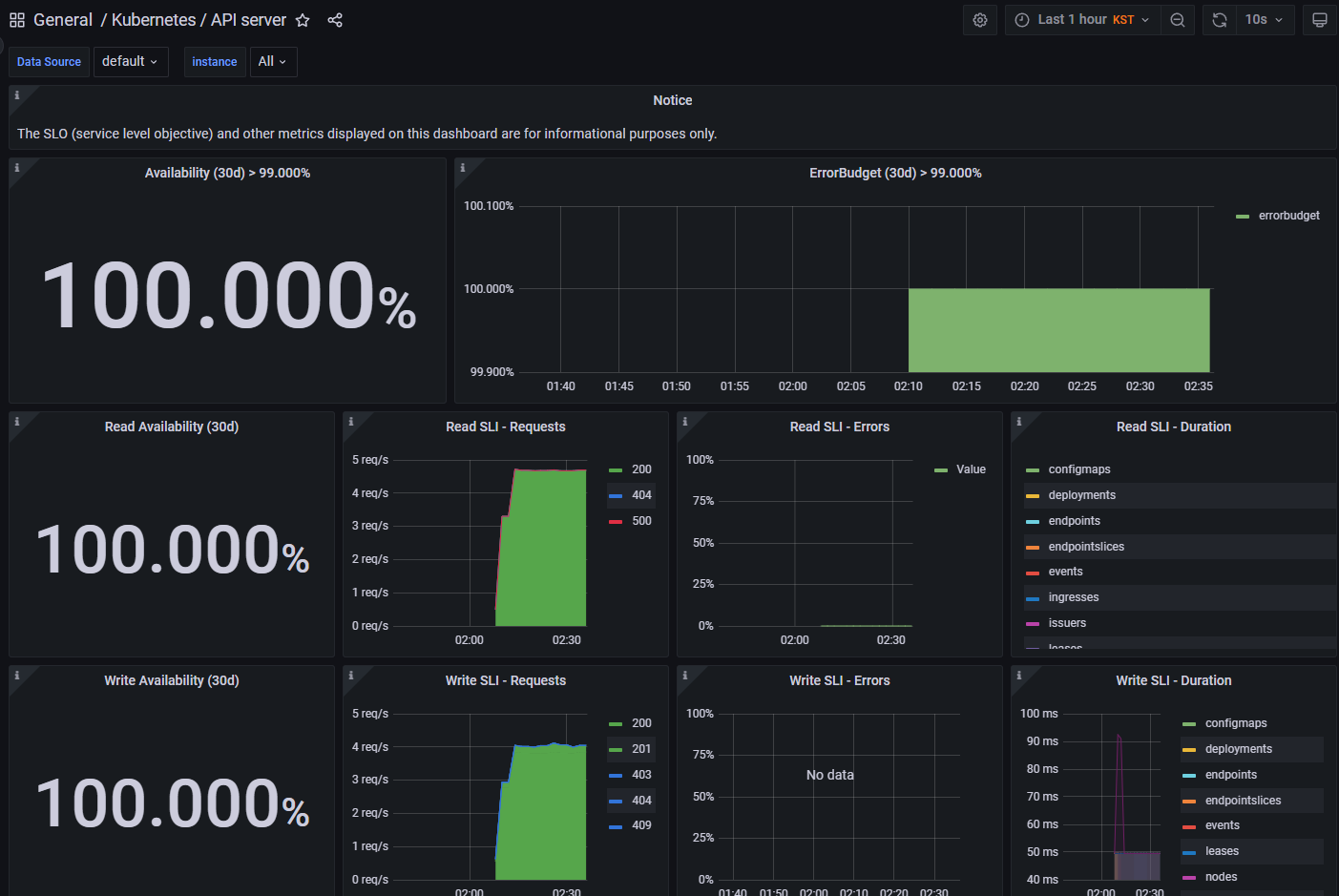
Grafana의 대시보드를 마음대로 Customizng 할 수 있어 원하는 데이터만 구성해서 볼 수 있지만,
처음 사용이 어렵다면 Grafana 공식 사이트에서 많은 사람들이 공유하는 Dashboard를 받아서 적용할 수 있다.
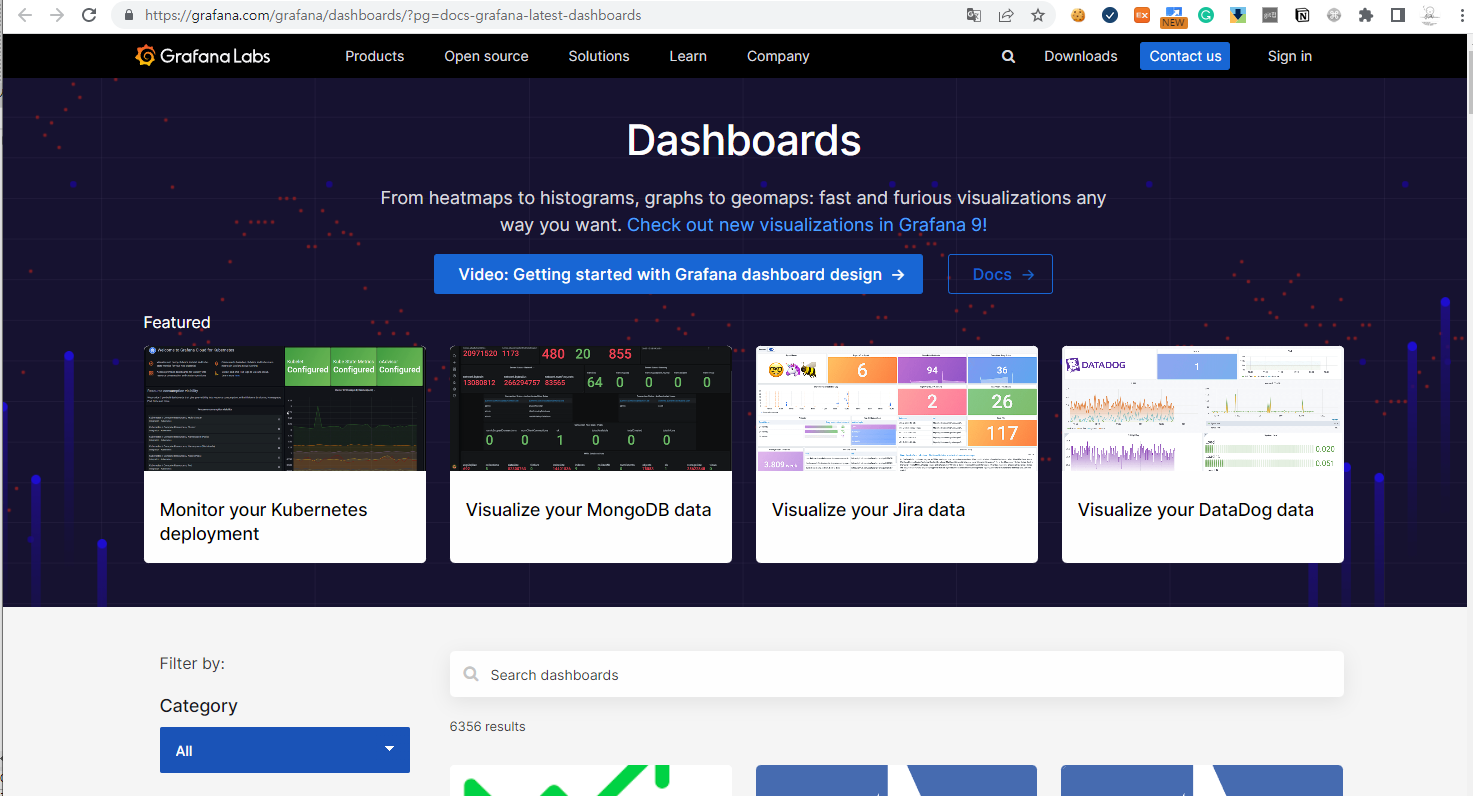
모니터링을 원하는 Data Source 종류에 따라 Dashboard를 선택하고 사이트에서 제공하는 ID(예시 : 13332)를 확인해
아래와 같이 적용하면된다.
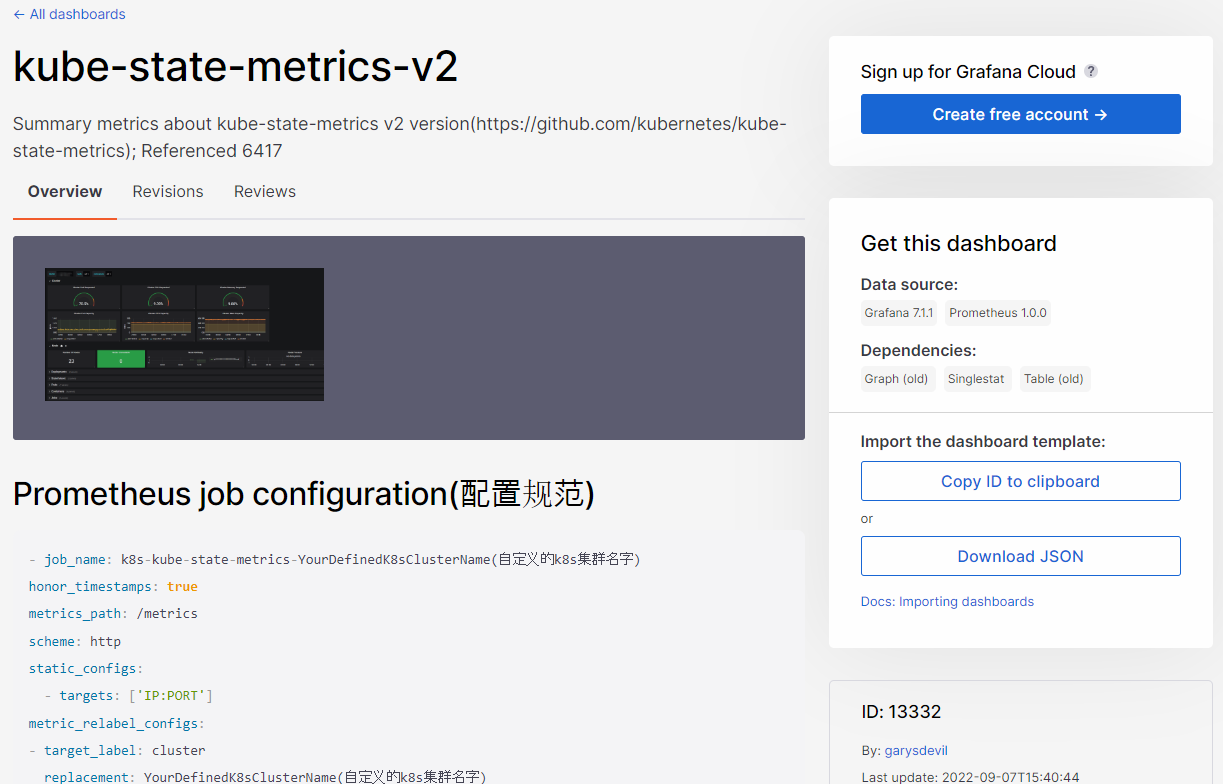
Grafana에서 Dashborads > Import dashboard 화면에서 확인한 ID를 입력 후 우측의 Load 버튼을 클릭한다.
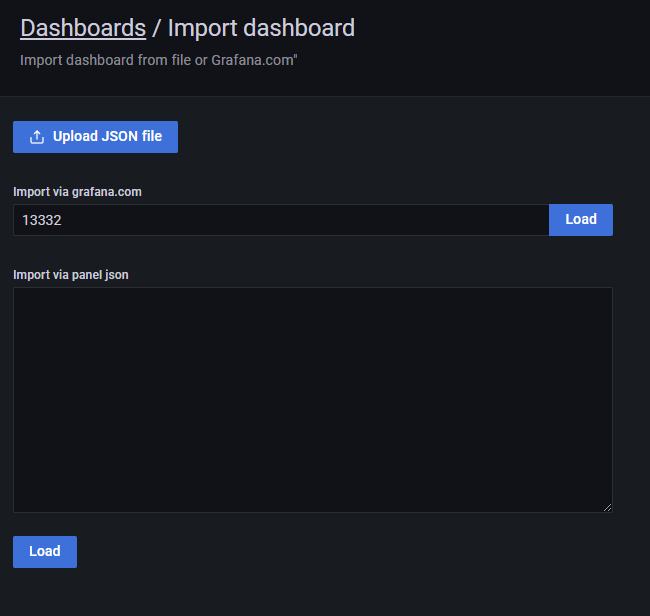
Load 후 Grafana에 등록된 Prometheus를 선택하고 Import를 수행한다.

(추가) Prometheus 기본 설치 후 발생하는 경보 확인
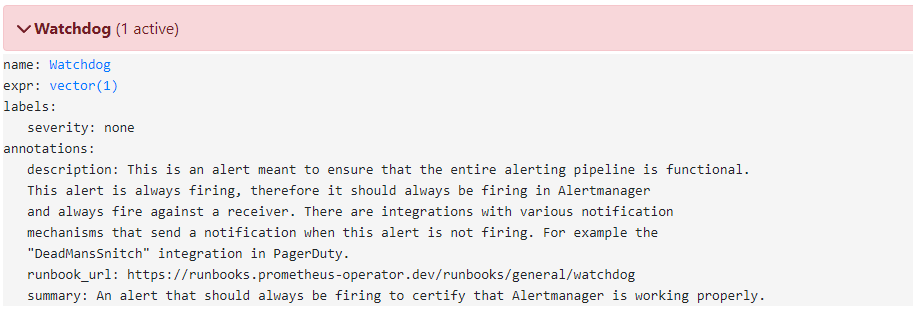
alertmanager의 알람 과정이 정상적으로 실행되는지 확인하기 위한 더미 알람이라고 한다.
(아무런 경보가 발생하지 않을 때 alertmanger가 정상동작하는지 확인이 어렵기 때문)
따라서 해당 알람은 따로 비활성화 하지 않는다.
참고 : https://github.com/prometheus/alertmanager/issues/2429


kube-controller-manager와 kube-scheduler가 다운되었다는 경보이다. 하지만 실제 조회를 해보면 정상적으로 기동 중인 것을 확인할 수 있다.
(ersia:default) [root@kops-ec2 ~]# kubectl get pod -n kube-system --show-labels | grep kube-controller-manager
kube-controller-manager-i-0e4134b86302cf16e 1/1 Running 2 (150m ago) 149m k8s-app=kube-controller-manager
(ersia:default) [root@kops-ec2 ~]# kubectl get pod -n kube-system --show-labels | grep kube-sche
kube-scheduler-i-0e4134b86302cf16e 1/1 Running 0 151m k8s-app=kube-scheduler이는 설치한 kube-prometheus-stack의 Label Selector가 k8s-app이 아닌 component를 사용하기 때문에 인식하지 못하는 것이므로, 해당 label을 추가해주거나 수정하면 정상적으로 인식한다.
// Selector 확인
(ersia:default) [root@kops-ec2 ~]# kubectl describe svc -n kube-system kube-prometheus-stack-kube-controller-manager
Name: kube-prometheus-stack-kube-controller-manager
Namespace: kube-system
Labels: app=kube-prometheus-stack-kube-controller-manager
...
...
release=kube-prometheus-stack
Annotations: meta.helm.sh/release-name: kube-prometheus-stack
meta.helm.sh/release-namespace: monitoring
Selector: component=kube-controller-manager ## 해당 selector를 확인할 수 있다.
Type: ClusterIP
...
...
(ersia:default) [root@kops-ec2 ~]# kubectl describe svc -n kube-system kube-prometheus-stack-kube-scheduler
Name: kube-prometheus-stack-kube-scheduler
Namespace: kube-system
Labels: app=kube-prometheus-stack-kube-scheduler
...
...
release=kube-prometheus-stack
Annotations: meta.helm.sh/release-name: kube-prometheus-stack
meta.helm.sh/release-namespace: monitoring
Selector: component=kube-scheduler ## 해당 selector를 확인할 수 있다.
Type: ClusterIP
...
...
// 설치할 때의 yaml 파일 확인
1203 kubeControllerManager:
1215 service:
1222 # selector:
1223 # component: kube-controller-manager ## 주석으로 기본 설치했기 때문에 발생한 경보
// Label 추가 작업
(ersia:default) [root@kops-ec2 ~]# kubectl label $(kubectl get pod -n kube-system -l k8s-app=kube-controller-manager -oname) -n kube-system component=kube-controller-manager
pod/kube-controller-manager-i-0e4134b86302cf16e labeled
(ersia:default) [root@kops-ec2 ~]#
(ersia:default) [root@kops-ec2 ~]# kubectl label $(kubectl get pod -n kube-system -l k8s-app=kube-scheduler -oname) -n kube-system component=kube-scheduler
pod/kube-scheduler-i-0e4134b86302cf16e labeled
// 추가된 Label 확인
(ersia:default) [root@kops-ec2 ~]# kubectl get pod -n kube-system --show-labels | grep kube-controller-manager
kube-controller-manager-i-0e4134b86302cf16e 1/1 Running 2 (163m ago) 163m component=kube-controller-manager,k8s-app=kube-controller-manager
(ersia:default) [root@kops-ec2 ~]#
(ersia:default) [root@kops-ec2 ~]# kubectl get pod -n kube-system --show-labels | grep kube-scheduler
kube-scheduler-i-0e4134b86302cf16e 1/1 Running 0 163m component=kube-scheduler,k8s-app=kube-scheduler

해당 에러는 namespace를 별도로 생성해서 발생하는 에러라고 생각했으나 해당 에러는 아니었다.
시간날 때 더 분석해볼 예정이다.
ALERTS{alertname="PrometheusOperatorRejectedResources", alertstate="firing", container="kube-prometheus-stack", controller="prometheus", endpoint="https", instance="172.30.83.240:10250", job="kube-prometheus-stack-operator", namespace="monitoring", pod="kube-prometheus-stack-operator-85857b9b68-n94bk", resource="ServiceMonitor", service="kube-prometheus-stack-operator", severity="warning", state="rejected"}
참고 : https://devocean.sk.com/search/techBoardDetail.do?ID=163168
구축한 kube-prometheus-stack 삭제
(ersia:default) [root@kops-ec2 ~]# helm uninstall -n monitoring kube-prometheus-stack
(ersia:default) [root@kops-ec2 ~]# kubectl delete ns monitoring
// kube-prometheus-stack에서는 테스트용으로 따로 구성하지 않아 별도로 필요하지 않다.
// 만약 helm chart에서 PVC 구성을 한다면 아래와 같은 PVC 삭제 작업이 필요할 수 있다.
(ersia:default) [root@kops-ec2 ~]# kubectl delete pvc --all -n monitoring
참고자료
- 모니터링 수집 방식(Push/Pull) : https://velog.io/@zihs0822/Push-vs-Pull-모니터링-데이터-수집-방식
- Add PodMonitor or ServiceMonitor outside of kube-prometheus-stack helm values : https://stackoverflow.com/questions/68085831/add-podmonitor-or-servicemonitor-outside-of-kube-prometheus-stack-helm-values
- kube-prometheus-stack : https://artifacthub.io/packages/helm/prometheus-community/kube-prometheus-stack
[24단계 실습으로 정복하는 쿠버네티스] 책으로 스터디를 진행하였다.
Prometheus란?
Prometheus는 시스템과 서비스를 모니터링하기 위한 도구로, Pull 방식의 모니터링 시스템과 경보 알람을 제공한다.
모니터링할 대상에 exproter라는 Agent가 설치되고 해당 Agent에서 다양한 모니터링 정보(Metric)을 수집해 놓으면 Prometheus Server에서 해당 데이터를 가져가는 방식을 취한다.
- 일반적으로는 Pull 방식을 취해 데이터를 수집하지만, Pushgateway를 통해서 짧은 수명의 작업(어플리케이션 등)은 Push 방식을 지원하는 것으로 확인된다.
- PromQL(Prometheus Query Language)이라는 질의언어를 제공한다. (일반적인 SQL은 아니지만 함수 등을 제공해 직관적이다.)
- 다양한 형태의 그래프를 제공하지만, Prometheus 자체로 제공하는 그래프는 다소 보기 어려워 Grafana라는 시각화 도구를 같이 사용한다.
Grafana란?
다양한 TSDB(Time Series DataBase)의 데이터(Metric, Log)를 보기편하게 시각화해주는 도구로, 시각화된 다양한 그래프와 경보 알람을 제공한다.
Prometheus & Grafana 구축
Kubernetes Operateor로 Helm을 통해 kube-prometheus-stack(Prometheus & Grafana 포함된 stack)을 비교적 간단히 설치할 수 있다.
kube-prometheus-stack 설치
// kube-prometheus-stack Chart 저장소 추가 및 최신화
(ersia:default) [root@kops-ec2 ~]# helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
"prometheus-community" has been added to your repositories
(ersia:default) [root@kops-ec2 ~]# helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "prometheus-community" chart repository
Update Complete. ⎈Happy Helming!⎈
// 추가 설정을 위해 로컬에 kube-prometheus-stack Chart 다운로드
(ersia:default) [root@kops-ec2 ~]# helm fetch prometheus-community/kube-prometheus-stack --untar
(ersia:default) [root@kops-ec2 ~]# tree kube-prometheus-stack -L 1
kube-prometheus-stack
├── Chart.lock
├── charts
├── Chart.yaml
├── CONTRIBUTING.md
├── crds
├── README.md
├── templates
└── values.yaml
3 directories, 5 files
// 아래의 내용을 수정
(ersia:default) [root@kops-ec2 ~]# vim ~/kube-prometheus-stack/values.yaml
140 alertmanager:
260 ingress:
261 enabled: true ## alertmanager의 ingress 사용
265 ingressClassName: alb ## ingressClasss는 alb로 사전 생성 후 통일해 사용
267 annotations: ## alb 관련 인증서 및 상세 설정
268 alb.ingress.kubernetes.io/scheme: internet-facing
269 alb.ingress.kubernetes.io/target-type: ip
270 alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
271 alb.ingress.kubernetes.io/certificate-arn: '{certificate-arn}' ## AWS인증서를 사용하기 위해 인증서의 ARN으로 입력
272 alb.ingress.kubernetes.io/success-codes: 200-399
273 alb.ingress.kubernetes.io/group.name: "monitoring" ## alertmanager, grafana, prometheus 모두 하나의 ingress Controller를 사용하기 위한 group설정
282 hosts:
283 - alertmanager.ersia.net ## alertmanger의 host 도메인
287 paths: ## alertmanger의 도메인 연결 시 path 사용 여부
288 - /* ## alertmanager, grafana, prometheus 모두 host 도메인으로 분리하므로 '/' Path 사용
756 grafana:
775 defaultDashboardsTimezone: Asia/Seoul ## Grafana의 기본 Timezone, 기본값은 utc
777 adminPassword: prom-operator ## Grafana의 웹 접속 시 초기 패스워드
784 ingress:
787 enabled: true ## grafana도 ingress를 사용할 예정이므로 true로 변경
792 ingressClassName: alb ## ingressClasss는 alb로 사전 생성 후 통일해 사용
796 annotations: ## alb 관련 인증서 및 상세 설정
797 alb.ingress.kubernetes.io/scheme: internet-facing
798 alb.ingress.kubernetes.io/target-type: ip
799 alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
800 alb.ingress.kubernetes.io/certificate-arn: '{certificate-arn}'
801 alb.ingress.kubernetes.io/success-codes: 200-399
802 alb.ingress.kubernetes.io/group.name: "monitoring"
813 hosts: ## grafana의 host 도메인
814 - grafana.ersia.net
817 paths: ## grafana 도메인 연결 시 path 사용 여부
818 - /*
2235 prometheus:
2492 ingress:
2493 enabled: true ## prometheus도 ingress를 사용할 예정이므로 true로 변경
2497 ingressClassName: alb
2499 annotations:
2500 alb.ingress.kubernetes.io/scheme: internet-facing
2501 alb.ingress.kubernetes.io/target-type: ip
2502 alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
2503 alb.ingress.kubernetes.io/certificate-arn: '{certificate-arn}'
2504 alb.ingress.kubernetes.io/success-codes: 200-399
2505 alb.ingress.kubernetes.io/group.name: "monitoring"
2516 hosts: ## prometheus의 host 도메인
2517 - prometheus.ersia.net
2521 paths: ## prometheus 도메인 연결 시 path 사용 여부
2522 - /*
2642 prometheusSpec: ## 참고 : https://stackoverflow.com/questions/68085831/add-podmonitor-or-servicemonitor-outside-of-kube-prometheus-stack-helm-values
2824 serviceMonitorSelectorNilUsesHelmValues: false ## 별도의 service,pod monitor를 사용할지 여부
2847 podMonitorSelectorNilUsesHelmValues: false ## false로 설정 후 제공하는 service,pod monitor를 통해 자동으로 prometheus target이 추가됨
2885 retention: 10d ## Metric 보관 주기, 10일이 지난 데이터는 주기적으로 삭제
2889 retentionSize: "10GiB" ## 데이터 저장을 위한 디스크 최대 사이즈, 10GiB가 되면 가장 오래된 데이터부터 삭제
// 모니터링용 Namespace 생성
(ersia:default) [root@kops-ec2 ~]# kubectl create ns monitoring
namespace/monitoring created
// 수정한 helm chart로 kube-prometheus-stack 설치
## 설치 시 command로 옵션을 추가로 입력할 수 있다.
## scrape_interval: 15s # 15초마다 metric을 수집한다. 기본값은 60초.
## evaluation_interval: 15s # 15초마다 설정된 경보를 보낼지 규칙을 확인하는 주기이다. 기본값은 60초.
(ersia:default) [root@kops-ec2 ~]# helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.8.1 \
> --set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
> -f ~/kube-prometheus-stack/values.yaml --namespace monitoring
NAME: kube-prometheus-stack
LAST DEPLOYED: Sun Apr 2 01:57:33 2023
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace monitoring get pods -l "release=kube-prometheus-stack"
Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
// 정상 설치 확인
(ersia:default) [root@kops-ec2 ~]# helm list -n monitoring
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kube-prometheus-stack monitoring 1 2023-04-02 01:57:33.124167646 +0900 KST deployed kube-prometheus-stack-45.8.1 v0.63.0
(ersia:default) [root@kops-ec2 ~]# kubectl get pod,svc,ingress -n monitoring
NAME READY STATUS RESTARTS AGE
pod/alertmanager-kube-prometheus-stack-alertmanager-0 2/2 Running 1 (77s ago) 83s
pod/kube-prometheus-stack-grafana-8fc98f79-8pzbz 3/3 Running 0 90s
pod/kube-prometheus-stack-kube-state-metrics-66566bbbf-s65dn 1/1 Running 0 90s
pod/kube-prometheus-stack-operator-85857b9b68-j86d5 1/1 Running 0 90s
pod/kube-prometheus-stack-prometheus-node-exporter-2gwrm 1/1 Running 0 90s
pod/kube-prometheus-stack-prometheus-node-exporter-cp2lc 1/1 Running 0 90s
pod/kube-prometheus-stack-prometheus-node-exporter-n58j8 1/1 Running 0 90s
pod/prometheus-kube-prometheus-stack-prometheus-0 2/2 Running 0 83s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 83s
service/kube-prometheus-stack-alertmanager ClusterIP 100.71.251.83 <none> 9093/TCP 90s
service/kube-prometheus-stack-grafana ClusterIP 100.66.173.8 <none> 80/TCP 90s
service/kube-prometheus-stack-kube-state-metrics ClusterIP 100.68.195.189 <none> 8080/TCP 90s
service/kube-prometheus-stack-operator ClusterIP 100.68.249.133 <none> 443/TCP 90s
service/kube-prometheus-stack-prometheus ClusterIP 100.68.245.242 <none> 9090/TCP 90s
service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 100.69.159.29 <none> 9100/TCP 90s
service/prometheus-operated ClusterIP None <none> 9090/TCP 83s
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress.networking.k8s.io/kube-prometheus-stack-alertmanager alb alertmanager.ersia.net k8s-monitoring-b219e55b0b-1120834911.ap-northeast-2.elb.amazonaws.com 80 90s
ingress.networking.k8s.io/kube-prometheus-stack-grafana alb grafana.ersia.net 80 90s
ingress.networking.k8s.io/kube-prometheus-stack-prometheus alb prometheus.ersia.net 80 90shttps://artifacthub.io/packages/helm/prometheus-community/kube-prometheus-stack#install-helm-chart
Node의 사양이 낮으면(c5a.large 기준) TargetGroup 활성화까지 5분 가량 소요되는 것으로 보인다.
정상적으로 설치가 완료되면 Ingress Controller(ALB) 1개가 생성된 것과 설정한 hostname이 ALB 규칙에 host로 입력된 것을 확인할 수 있다.
(ersia:default) [root@kops-ec2 ~]# kubectl get ingress -n monitoring
NAME CLASS HOSTS ADDRESS PORTS AGE
kube-prometheus-stack-alertmanager alb alertmanager.ersia.net k8s-monitoring-b219e55b0b-196433738.ap-northeast-2.elb.amazonaws.com 80 2m19s
kube-prometheus-stack-grafana alb grafana.ersia.net k8s-monitoring-b219e55b0b-196433738.ap-northeast-2.elb.amazonaws.com 80 2m19s
kube-prometheus-stack-prometheus alb prometheus.ersia.net k8s-monitoring-b219e55b0b-196433738.ap-northeast-2.elb.amazonaws.com 80 2m19s
kube-prometheus-stack 설치 후 Promethus 웹페이지 접속
설치 시 입력한 host URL로 접속하면 로그인 가능한 웹페이지를 확인할 수 있다. (예시 : promethus.ersia.net)
promethus에는 별도의 인증없이 접속 가능하다.
kube-prometheus-stack로 설치하면 promethus 단독 설치와는 다르게 기본적인 rule이나 alert 설정이 되어있다.
- Alerts : Promethus에서 확인된 경보 목록(알람 발생/미발생/보류 포함)을 조회할 수 있다, 현재까지 진행된 설정으로 설치 시 4개 가량의 Alert가 발생해있다.
- Graph : PromQL을 사용해 수집된 메트릭 정보를 조회할 수 있다.
- Status : Promethus 설정, Alert 규칙 설정 및 조회, 모니터링 대상 확인 등의 정보를 확인할 수 있다.
필수 기능은 모두 제공되지만 시각화나 그래프 형태로 조회하기엔 조금 어려움이 있는데,
이런 그래프와 시각화를 Grafana를 통해 해결할 수 있다.
Grafana 웹페이지 접속
설치 시 입력한 host URL로 접속하면 로그인 가능한 웹페이지를 확인할 수 있다. (예시 : grafana.ersia.net)
초기 로그인 정보는 admin / 설치시 정의한 초기 패스워드(prom-operator)이다.
로그인 후 맨 왼쪽 하단의 Configuration > Data Sources > 에서 Data Source를 추가해 데이터 시각화를 사용할 수 있으며,
kube-prometheus-stack로 설치하면 기본값으로 Prometheus를 자동 설정해준다.
맨 왼쪽 상단의 Dashboards > Browse 에서 추가한 Data Sources를 Dashboard로 다양한 시각화 그래프를 제공하는데,
초기 설정에서는 기본적인 Kubernetes 정보에 대한 Dashboard를 확인할 수 있다.
Grafana의 대시보드를 마음대로 Customizng 할 수 있어 원하는 데이터만 구성해서 볼 수 있지만,
처음 사용이 어렵다면 Grafana 공식 사이트에서 많은 사람들이 공유하는 Dashboard를 받아서 적용할 수 있다.
모니터링을 원하는 Data Source 종류에 따라 Dashboard를 선택하고 사이트에서 제공하는 ID(예시 : 13332)를 확인해
아래와 같이 적용하면된다.
Grafana에서 Dashborads > Import dashboard 화면에서 확인한 ID를 입력 후 우측의 Load 버튼을 클릭한다.
Load 후 Grafana에 등록된 Prometheus를 선택하고 Import를 수행한다.
(추가) Prometheus 기본 설치 후 발생하는 경보 확인
alertmanager의 알람 과정이 정상적으로 실행되는지 확인하기 위한 더미 알람이라고 한다.
(아무런 경보가 발생하지 않을 때 alertmanger가 정상동작하는지 확인이 어렵기 때문)
따라서 해당 알람은 따로 비활성화 하지 않는다.
참고 : https://github.com/prometheus/alertmanager/issues/2429
kube-controller-manager와 kube-scheduler가 다운되었다는 경보이다. 하지만 실제 조회를 해보면 정상적으로 기동 중인 것을 확인할 수 있다.
(ersia:default) [root@kops-ec2 ~]# kubectl get pod -n kube-system --show-labels | grep kube-controller-manager
kube-controller-manager-i-0e4134b86302cf16e 1/1 Running 2 (150m ago) 149m k8s-app=kube-controller-manager
(ersia:default) [root@kops-ec2 ~]# kubectl get pod -n kube-system --show-labels | grep kube-sche
kube-scheduler-i-0e4134b86302cf16e 1/1 Running 0 151m k8s-app=kube-scheduler이는 설치한 kube-prometheus-stack의 Label Selector가 k8s-app이 아닌 component를 사용하기 때문에 인식하지 못하는 것이므로, 해당 label을 추가해주거나 수정하면 정상적으로 인식한다.
// Selector 확인
(ersia:default) [root@kops-ec2 ~]# kubectl describe svc -n kube-system kube-prometheus-stack-kube-controller-manager
Name: kube-prometheus-stack-kube-controller-manager
Namespace: kube-system
Labels: app=kube-prometheus-stack-kube-controller-manager
...
...
release=kube-prometheus-stack
Annotations: meta.helm.sh/release-name: kube-prometheus-stack
meta.helm.sh/release-namespace: monitoring
Selector: component=kube-controller-manager ## 해당 selector를 확인할 수 있다.
Type: ClusterIP
...
...
(ersia:default) [root@kops-ec2 ~]# kubectl describe svc -n kube-system kube-prometheus-stack-kube-scheduler
Name: kube-prometheus-stack-kube-scheduler
Namespace: kube-system
Labels: app=kube-prometheus-stack-kube-scheduler
...
...
release=kube-prometheus-stack
Annotations: meta.helm.sh/release-name: kube-prometheus-stack
meta.helm.sh/release-namespace: monitoring
Selector: component=kube-scheduler ## 해당 selector를 확인할 수 있다.
Type: ClusterIP
...
...
// 설치할 때의 yaml 파일 확인
1203 kubeControllerManager:
1215 service:
1222 # selector:
1223 # component: kube-controller-manager ## 주석으로 기본 설치했기 때문에 발생한 경보
// Label 추가 작업
(ersia:default) [root@kops-ec2 ~]# kubectl label $(kubectl get pod -n kube-system -l k8s-app=kube-controller-manager -oname) -n kube-system component=kube-controller-manager
pod/kube-controller-manager-i-0e4134b86302cf16e labeled
(ersia:default) [root@kops-ec2 ~]#
(ersia:default) [root@kops-ec2 ~]# kubectl label $(kubectl get pod -n kube-system -l k8s-app=kube-scheduler -oname) -n kube-system component=kube-scheduler
pod/kube-scheduler-i-0e4134b86302cf16e labeled
// 추가된 Label 확인
(ersia:default) [root@kops-ec2 ~]# kubectl get pod -n kube-system --show-labels | grep kube-controller-manager
kube-controller-manager-i-0e4134b86302cf16e 1/1 Running 2 (163m ago) 163m component=kube-controller-manager,k8s-app=kube-controller-manager
(ersia:default) [root@kops-ec2 ~]#
(ersia:default) [root@kops-ec2 ~]# kubectl get pod -n kube-system --show-labels | grep kube-scheduler
kube-scheduler-i-0e4134b86302cf16e 1/1 Running 0 163m component=kube-scheduler,k8s-app=kube-scheduler
해당 에러는 namespace를 별도로 생성해서 발생하는 에러라고 생각했으나 해당 에러는 아니었다.
시간날 때 더 분석해볼 예정이다.
ALERTS{alertname="PrometheusOperatorRejectedResources", alertstate="firing", container="kube-prometheus-stack", controller="prometheus", endpoint="https", instance="172.30.83.240:10250", job="kube-prometheus-stack-operator", namespace="monitoring", pod="kube-prometheus-stack-operator-85857b9b68-n94bk", resource="ServiceMonitor", service="kube-prometheus-stack-operator", severity="warning", state="rejected"}
참고 : https://devocean.sk.com/search/techBoardDetail.do?ID=163168
구축한 kube-prometheus-stack 삭제
(ersia:default) [root@kops-ec2 ~]# helm uninstall -n monitoring kube-prometheus-stack
(ersia:default) [root@kops-ec2 ~]# kubectl delete ns monitoring
// kube-prometheus-stack에서는 테스트용으로 따로 구성하지 않아 별도로 필요하지 않다.
// 만약 helm chart에서 PVC 구성을 한다면 아래와 같은 PVC 삭제 작업이 필요할 수 있다.
(ersia:default) [root@kops-ec2 ~]# kubectl delete pvc --all -n monitoring
참고자료
- 모니터링 수집 방식(Push/Pull) : https://velog.io/@zihs0822/Push-vs-Pull-모니터링-데이터-수집-방식
- Add PodMonitor or ServiceMonitor outside of kube-prometheus-stack helm values : https://stackoverflow.com/questions/68085831/add-podmonitor-or-servicemonitor-outside-of-kube-prometheus-stack-helm-values
- kube-prometheus-stack : https://artifacthub.io/packages/helm/prometheus-community/kube-prometheus-stack